
What is the Grid? Page 1 | Page 2
Extract of PhD Thesis [ pdf ]: Chapter 2 background
A compute cluster consists of multiple nodes that are capable of performing computational tasks. Clusters are increasingly built by assembling commodity machines that have one or even several CPUs and CPU cores and are networked. In the context of this thesis, it is unimportant whether the networking is achieved using commodity (e.g., Ethernet) or specialist networks (e.g., Myrinet). Clusters are used in computational science typically when tasks are relatively independent of each other and have sufficiently modest memory requirements that they can be farmed out to different nodes of the cluster. These tasks are referred to as jobs. Jobs suited for execution on clusters are typically batch jobs, requiring no input from a user during execution, and can execute in a serial manner, where each job is fully independent, or parallel manner – where multiple instances of a job running on different nodes may be required to interact with each other. Specialist interfaces exist for parallel jobs such as the Message Passing Interface (MPI) or the Parallel Virtual Machine (PVM), which enable interaction where shared memory in a cluster may or may not be available.
The process of allocating jobs to individual nodes of a cluster is handled by a distributed resource manager (DRM). The DRM allocates the job to a node using some resource allocation policy that may take into account node availability, user priorities, job waiting time, etc. Examples of popular resource managers include Condor (Tannenbaum et al., 2001), the Sun Grid Engine (SGE) (Gentzsch, 2001), and the Portable Batch Queuing System (PBS) (Henderson, 1995). These typically provide submission and monitoring primitives enabling users or applications to specify jobs to be executed and keep track of the progress of execution. Jobs will be specified as a collection of requirements, specifying the files required for the execution, such as executables and data files, the execution parameters, such as arguments, standard streams and environmental variables, and finally potential platform requirements, such as operating system, memory, etc. – for resource managers like Condor that cater for heterogeneous clusters.
In addition to status and monitoring primitives, DRMs will usually provide resource discovery primitives, providing users with the means to obtain information about the resources that constitute the cluster, such as their status, load, availability, etc. and, for heterogeneous clusters, resource specification details such as operating system, memory etc.
When dealing with multiple resources, the question of how these resources can be accessed and used as a single integrated service must be answered. This requires solution of a great number of problems, including authentication and authorisation, secure file transfer, distributed storage management and resource scheduling across organisational boundaries, which is the focus of this thesis.
In order to facilitate remote access and unified use of resources, several grid middleware systems have been developed to resolve the differences that exist between submission, monitoring and query interfaces of the various DRMs in use.
The Globus toolkit (Foster, 2005) is an open source project that provides a number of components to standardize various aspects of remote interaction with DRMs. With respect to compute DRMs, it provides a platform-independent job submission interface, the Globus Resource Allocation Manager (Czajkowski et al., 1998), a security framework, the Grid Security Infrastructure(GSI) (Welch et al., 2003), and information management components, the Monitoring and Discovery Service (Zhang & Schopf, 2004). Interactions with the various components of the Globus toolkit are mapped to local management system specific calls and support is provided for a wide range of DRMs, including Condor, PBS and SGE.
Similarly, GridSAM (Lee et al., 2004) provides a common job submission and monitoring interface to multiple underlying DRMs. As a Web Service based submission service, it implements the Job Submission Description Language (JSDL) (Anjomshoaa et al., 2005), a Global Grid Forum specification aiming to standardize job requirement specification documents. It implements a collection of DRM plug-ins that map JSDL requests and monitoring calls to system-specific calls. These standardised interfaces and tools provide the building blocks for a grid scheduling framework, and we rely primarily on GridSAM to provide basic access to remote resources. Both GridSAM and JSDL will be covered in more detail below.
By pooling together independent nodes and clusters into grids, scientists have aimed to increase the computational power available to tackle larger scientific problems and handle increasingly demanding applications. (Sun Microsystems, 2003) identify three levels of deployment for computational grids, illustrated in Figure 2.1:
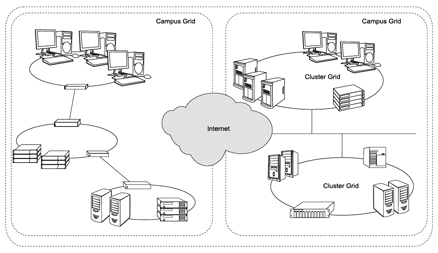
- Cluster Grids: Confined to a single administrative domain, cluster grids will normally operate according to a centralized scheduling and policy management system enforced by the DRM in use.
- Campus Grids: Confined to the boundaries of a single organization, campus grids link together clusters and resources across multiple administrative domains.
- Global grids: Global grids link together clusters and campus grids across organizational boundaries, allowing organizations to tap into resources of other organizations.
While this categorization does allow us to appreciate the scale of grid computing, it is important to refine the definition of what constitutes a grid. We deviate in part from the above by adopting the following definition (Coveney, 2005):
“Grid computing is distributed computing performed transparently across multiple administrative domains.”.
Indeed a cluster may be formed of a heterogeneous set of nodes, but what crucially distinguishes grid computing from other forms of distributed computing is the challenges brought from operation across administrative boundaries. In particular the notion of site autonomy, which will be discussed in Chapter 3, implies potentially different allocation policies and objectives at each location contributing resources to a grid, requiring scheduling of tasks to take into account any divergence in this regard to ensure that the process remains transparent to the end users.
In addition, the distinction between Campus and Global grids merits further discussion. Both may present similar requirements, but key differences do exist. They require means of integrating independent resources into a unified framework and the need to operate across several administrative domains means that both grid settings proscribe fully centralized approaches to scheduling and policy management. In a campus grid however, a higher level of trust and geographical proximity makes it easier for administrators to achieve a consensus on resource behaviour that will ensure consistency throughout the institution and benefit both users and providers.
As it is not always possible to establish such agreements across institutions, we must, in order to address the requirements of grids at any level of deployment, adopt a fully decentralized approach to resource aggregation across sites: each individual resource management system must become capable of making decisions as to how to handle incoming requests, based on its own perception of the state of the virtual organization(s) it currently belongs to and an understanding of its individual contribution. Notions that are implicit in campus grids, such as trust, need to be explicitly defined in a global grid and taken into account when scheduling and allocating resources. In order to protect the interests of individual sites, principles and mechanisms that do not impact on site autonomy, such as recommendation and reputation, should be favoured over centralized policy management approaches, whilst compensating for the lack of direct control over resources not in the immediate administrative domain. Centralized approaches may have an impact on the control that providers have over their own resources, which may in turn affect their willingness to contribute these resources.