RESEARCH SUMMARY
My research focuses on the intersection of computer vision, computer graphics, display technologies and human computer interaction. My main objective is to push the boundaries of what humans can do with large video collections and multiple video streams and how they interact with them. Mobile phones and portable devices have created novel ways to capture images and videos and have now entered the mainstream market - this has resulted in a dramatic increase of data available online and offline. Motion sensing cameras such as Kinect promise to have a similarly profound effect on how we use computers. While this opens up exciting opportunities for the research communities, it is not clear what is the best way to handle this large amount of data and display it. In particular, for video collections or large camera networks, presenting those data such that system's spatiality and users' spatial thinking are maximised presents a hard challenge which is to date still an open problem.
My primary research interest is to study the effect and benefits of spatially localised videos. However, my research also looks at the impact of display technologies on users' performance and to 3D reconstruction for telecommunications systems and augmented reality (AR) technologies and applications. I have explored the field of video+focus and video in context for both telepresence and browsing systems, and studied the impact of these representations on users' perception and understanding. Additionally, one of my research interest is the development of algorithms for fast 3D reconstruction of medium to small sized environments. To this extent, recently, I have started to work with "depth-cameras" (i.e. cameras that can acquire a continuous stream of depth information), developing solutions for adapting them to 3D reconstruction and network streaming.
I am also actively researching ways to build heterogeneous camera networks for collaborative mixed reality systems. My final goal is to obtain a smart network that can offer to the users the highest quality representation of the virtual environment in which it operates.
In general I am interested in several problems related to Computational Photography, Image Processing and Computer Vision such as Image classification, 3D models from Images and Videos and development of fast and efficient algorithm to generate and manipulate high quality images. Moreover, I am also researching to improve High Dynamic Range imagery, as my final aim is to adapt this particular technique to every kind of scene.
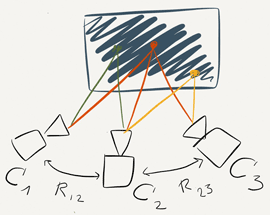
Heterogenous Cameras Network. The work conducted in my research aims at integrating different camera types
in an heterogeneous network that supports novel rendering solutions for telecommunication and offline replay. Steps to achieve this include data acquisition, 3D scene reconstruction and data fusion, streaming and rendering. I am interested in developing solutions that are able to create, in a limited amount of time, a detailed and accurate reconstruction of a static environment, which however, still supports live (or offline) updates.
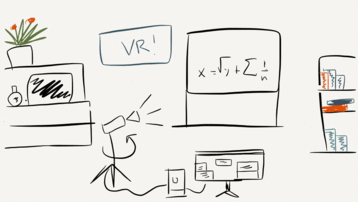
3D Scene Acquisition. During the last few years, the application of 3D reconstruction algorithms have been extended in a large number of fields such as architecture, design, film industry or medical research. Nevertheless, 3D reconstruction remains an open problem, whose performance largely depends on the algorithm employed and the input. Few 3D reconstruction algorithms can reach the level of details needed for virtual reality systems, and virtually no solutions can cope with the interactive rates required by remote collaborations. However, the recent increase of hardware capabilities and a larger availability of off-the-shelf solutions for depth acquisition have given a strong boost to the research in this field, which resulted in a revamped interest in real-time 3D reconstruction.
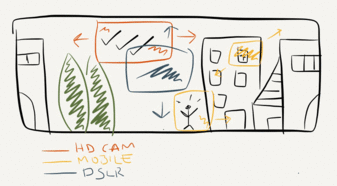
Video in Context. Similarly to the heterogeneous cameras network topic, video in context tries to link together a collection of video or live stream and localise them within a given context. The context can be a hand-modelled 3D model, a range-camera acquired point-cloud or a panoramic image of a location. Localisation is performed by fusing together a large range of data, such as sensor data, gps locations or vision-based tracking. Besides methods to track and render such heterogeneous data, I am interested in exploring the impact of video in context on user performances when performing tasks that require spatially-localised reasoning, such as remote collaboration, offline and online video lingering analysis or video browsing.