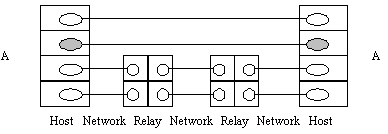
 Figure 1. Network interconnection
Figure 1. Network interconnection
Figure 1. Network interconnection
Very many different methods are used to connect networks together but it is possible to identify some common features. Interconnection takes place in a particular layer. In that layer and below, the networks are separate, above it, the networks appear as one. This is illustrated in figure 1 which shows two hosts connected across three networks with the networks being interconnected by systems termed "relays" (see below). Above the interface labelled "A" the protocols operate "end-to-end" ("host-to-host"). Below it, individual networks are visible and protocols are not end-to-end. Ideally the two shaded protocol entities should not be aware of the complexities which exist below them. For example, we would expect them to work perfectly happily if we eliminated the relays and attached the two hosts to a single network. We say that the interconnection is "transparent" to them. A very well known example of this sort of thing is the Internet in which the shaded entities would be implementing the TCP protocol whilst the next layer down would use the Internet IP protocol. When you install TCP software on a host you do not have to tell it what configuration of networks and relays it is likely to operate across. This fact demonstrates that the interconnection is transparent to TCP.
In terms of the OSI model TCP operates in the Transport layer and IP in the Network layer. Transport protocols are end-to-end by definition so generally we find network interconnection taking place in the Network layer or below - but there are exceptions!
Various terms are used to describe devices which interconnect networks. Unfortunately there is poor agreement as to precisely what each term means. The following terms will be encountered:
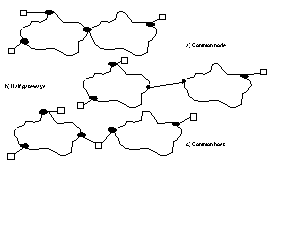 Figure 2. Position of gateways
Figure 2. Position of gateways
A lot depends on who owns the networks being interconnected. If they are both owned by the same organisation (as is normally the case with a LANLAN MAC bridge) then the device may be a common node on the two networks (Figure 2a)
If the networks are owned by different organisations (as is the case of an international interconnection between two public X.25 networks) then common ownership of a gateway may not be acceptable. Instead, the gateway may be split into two (Figure 2b) and a protocol defined to allow the two halfgateways to communicate. This may also be a good solution where the two networks are owned by the same organisation but are separated by a considerable physical distance. Thus a MAC bridge, whilst remaining logically a single unit, may be split into two half bridges linked by (say) an ISDN channel.
Finally, a third party may be attached as a host to two networks neither of which it owns. It can then act as a host on the two networks whilst relaying data between them (Figure 2c). (There may be regulatory problems if two public networks are connected in this way.)
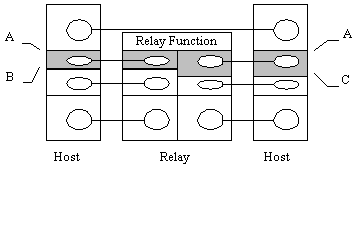 Figure 3. Service Relay
Figure 3. Service Relay
In figure 3 the service at interface "A" is common to all hosts and relays. This is particularly advantageous as it makes the "Relay Function" very simple to specify. In response to ?.inds and ?.confs received from one side it generates ?.reqs and ?.resps on the other. The "objects" that are being relayed are effectively (N)SDUs and we have what is called a "service relay".
In fact the service relay model is so advantageous that it is worth doing some work to achieve it. In figure 3 the interfaces "B" and "C" correspond to the "native" services offered by the two networks. These may very well be quite different; for example one might be a CL MAC service on a LAN whilst the other could be a circuit-switched service on the ISDN. The shaded layers in figure 3 are adaptation layers designed to bring the two native services to a common service. One of the principle reasons for the success of the Internet is the existence of adaptation standards for a very wide range of native services and the widespread support of these by manufacturers. For example, router and host manufacturers typically offer a range of network interfaces on their products (IEEE 802 LANs, MANs, X.25 WAN, ISDN etc. etc.) and for each of these they provide the appropriate IP adaptation software.
In a service relay the protocols in the adaptation layer and below "terminate" at the relay (see figure 3). Note that:
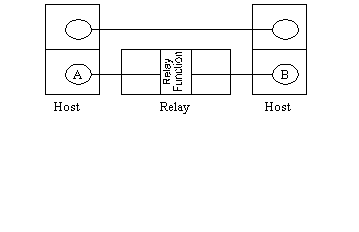 Figure 4. Protocol Relay
Figure 4. Protocol Relay
If the protocols used one either side of a relay are sufficiently similar then an alternative approach is possible. Here the relay does not have proper protocol entities. Instead it has an entity which receives a PDU from one side and simply passes this on the other - perhaps making minor adjustments to the format etc. (Figure 4). In this case, the objects which are being relayed are PDUs not SDUs. The entities A and B are not aware of the presence of a relay, they talk directly to each other. This is a much less general approach but it does put less load on the relay. For example, there is no need for the relay to examine sequence numbers in PDUs, it simply passes everything on and leaves any problems to be resolved by the "end" protocol entities.
Any network technology which is capable of switching must employ some sort of addressing scheme which it uses to identify the points at which hosts attach to it. These addresses are collectively known as "Sub-Network Point of Attachment (SNPA) Addresses". Examples are:
Within such schemes one finds an administrative mechanism which guarantees uniqueness of addresses. This is often through a hierarchical devolution of responsibility. E.g. the International Telecommunications Union (ITU) allocates country codes then leaves it to individual countries to allocate area codes etc. However:
If we are to connect all these technologies into a single "internet" then we must introduce a new addressing scheme which is independent of all the technology-based ones.
In the end, our data must be carried through existing technologies and these technologies will continue to understand only their own particular addressing schemes. We will need to be able to map our "internet" addresses onto the local technology-based addresses. This is called "address resolution".
Two schemes are relevant to us; the Internet scheme and the OSI scheme.
An Internet IP address is four bytes long which is conventionally written as four decimal numbers separated by dots as in 128.16.5.2. The lefthand part of an IP address identifies an "IP network", the rest identifies a host on that network. The connection between one IP network and the next is effected by an "IP router" - a service relay. An "IP network" may correspond to a physical network like an Ethernet - but it need not. This is the case at UCLCS, for example, where several "logical" networks exist which have no particular correspondence with physical networks. This is done so as to exploit another feature of IP routers their ability to apply intelligent filters to traffic. For example, we might put all student machines on one IP network and then instruct a router to block IP traffic from these machines to the outside world.
The dividing line between the network and host parts of an IP address is variable as follows:
| 0NNNNNNN | HHHHHHHH | HHHHHHHH | HHHHHHHH |
| 10NNNNNN | NNNNNNNN | HHHHHHHH | HHHHHHHH |
| 110NNNNN | NNNNNNNN | NNNNNNNN | HHHHHHHH |
Thus 128.16.5.2 (a UCLCS host) is of the second type. 128.16 identifies a UCL-CS network. The remaining 16 bits allow up to 65536 host addresses to be allocated. It should be clear that this format supports hierarchical routing with the IP networks playing the role of the "areas" in Notes 13.
IP network addresses are allocated to organisations by the Internet's naming and addressing authority. Organisations are then free to allocate the host parts as they wish.
ISO have defined two global network services; one CO and one CL. The CL service is very similar to the Internet IP service. Hosts which use either of these services are said to be attached to them at "Network Service Access Points" (NSAPs) and it is these which are identified by the global addresses.
The chief aims of the designers of the OSI "NSAP Address" scheme were to ensure addresses would be globally unique and to accommodate existing schemes. "Existing schemes" include things like the ISDN numbering scheme ("E.164") and the X.25 addressing scheme ("X.121") which already have addressing authorities in place to ensure uniqueness. Figure 5 shows the format:
| ÚÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÂÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄ¿
³ÚÄÄÄÄÄÂÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄ¿³ ³ ³³ AFI ³ IDI ³³ DSP ³ ³ÀÄÄÄÄÄIDPÄÄÄÄÄÄÄÄÄÄÄÄÄÙ³ ³ ÀÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÁÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÄÙ |
IDP is the "Initial Domain Part" which is itself divided in two:
The main function of the "Authority and Format Identifier" (AFI) is to identify who is the toplevel naming authority.
The "Initial Domain Identifier" (IDI) is a value allocated by that authority which effectively identifies the next authority in the hierarchy. In practice the top level authority is always ISO or CCITT in various guises. Some sample values are:
For example, in the second case, the IDI might be 0713833322 which is one of UCLCS's ISDN numbers. No one else is entitled to use this in an NSAP address so UCLCS must be the authority for the rest of the address the "Domain Specific Part" (DSP). UCLCS may allocate DSP values any way they choose, for example they may decide to use part of it to identify subnetworks and part to identify hosts in a manner similar to IP.
This scheme is a bit of a mess. It satisfies the design aims but at the expense of generating very long addresses - up to 40 digits in some cases. Worse still:
 Figure 6. Internetwork routing
example
Figure 6. Internetwork routing
example
We illustrate the steps involved by considering the passage of a packet through the internetwork in figure 5. Here A is a token ring, B is an Ethernet, X and Y are hosts and R is an Internet router (i.e. a service relay). X wishes to send an IP datagram to Y. There are 4 points of attachment present; one each for X and Y and 2 for the router. Each of these will have an SNPA address - MAC addresses in this case. Each must also have an IP address. Since A and B are connected via a router, Internet rules state that they must operate as separate IP "networks"- say 128.16 and 192.40 respectively. Thus the addresses might be as in table 1 (note that the actual values of the SNPA addresses are irrelevant so these are represented symbolically.
| Interface | SNPA Address | IP address |
| X | xxxxxxxxxxxxxxx | 128.16.5.2 |
| R1 | r1r1r1r1r1r1r1r | 128.16.6.7 |
| R2 | r2r2r2r2r2r2r2r | 192.40.6.8 |
| Y | yyyyyyyyyyyyyyy | 192.40.15.23 |
We begin with the IP-level processing. Inside X we construct an IP datagram with source address 128.16.5.2 and destination address 192.40.15.23. The IP routing software in X determines that the destination is on a "foreign" network and maps the network part of the destination address onto a suitable router - R1 in this case:
192.40 128.16.6.7 (next hop)
We now need to dispatch the datagram across the token ring. For this we need the token ring MAC address of R1, this is the address resolution step:
128.16.6.7 r1r1r1r1r1r1r1r
We can now place the complete IP datagram in a token ring frame and send it to R. This frame includes 4 addresses:
| Destination SNPA | r1r1r1r1r1r1r1r |
| Source SNPA | xxxxxxxxxxxxxxx |
| Destination IP | 192.40.15.23 |
| Source IP | 128.16.5.2 |
R extracts the IP datagram and looks up the destination address in its routing table. It finds that network 192.40 is accessible via its interface 2 and, in fact is directly attached to it.
192.40 Interface 2, 192.40.15.23 (next hop)
We now need to dispatch the datagram across the Ethernet. For this we need the Ethernet MAC address of Y, this is the address resolution step again:
192.40.15.23 yyyyyyyyyyyyyyy
We can now place the complete IP datagram in an Ethernet frame and send it to Y. This frame includes 4 addresses:
| Destination SNPA | yyyyyyyyyyyyyyy |
| Source SNPA | r2r2r2r2r2r2r2r |
| Destination IP | 192.40.15.23 |
| Source IP | 128.16.5.2 |
The mappings above are accomplished through consultation of tables held in local memory. These tables may be maintained entirely through human input. However, automatic maintenance is often possible. IP routing information may be updated via a dynamic routing protocol like the "Routing Information Protocol" (RIP). On LANs the address resolution tables may be maintained through a mechanism based on broadcast as described below.
In the example above, if R does not have the SNPA address of Y in it tables it broadcasts an Address Resolution Protocol (ARP) PDU on the Ethernet which says, effectively, "who is 192.40.15.23?". Y replies with "its me and my Ethernet address is yyyyyyyyyyyyyyy". In fact Y broadcasts its reply so that all the other hosts on the Ethernet can note the mapping.
The layer favoured by ISO and the Internet is the Network Layer. This makes sense for three reasons:
Unfortunately, ISO have introduced features into their Network layer which make relaying less easy than it should be. The major problem is the existence of two quite separate and completely incompatible Network services; CONS and CLNS. It is quite impossible to build a relay between these two services. If one subnetwork has only CONS and the other only CLNS then one or both must be adapted to support the other class of service.
For LANs, the MAC bridge is common, lightweight alternative. The MAC bridge is a service relay and, because the MAC Service is so simple, a MAC bridge has very little processing to do and so can have a very high performance. Equally important, the MAC bridge is transparent to higher layers. It can happily pass a mixture of IP datagrams, Novell IPX datagrams and OSI CONS PDUs for example.
The CO/CL dilemma leads also to interconnection in the Transport Layer. This is because all the OSI applications specified so far are built on COTS. Thus two subnetworks are likely to share the same Transport service even if their Network services are different. This is a good pragmatic solution but sits extremely uneasily with the OSI model which insists that transport protocols are endtoend.
Finally, situations arise in which two networks have no compatibility in any layers. This would be the case when connecting (say) a pure X.25 network to one operating Internet protocols. Here, one may resort to an "application relay". For example, the terminal protocol used in the Internet ("telnet") is completely different from that used in X.25 networks (X.29). However, both do much the same job, therefore it is possible to construct a relay between them allowing users on the X.25 network to login to hosts on the Internet.
A second reason for using application relays relates to management. As an example, there may be a need for interworking of terminal protocols but the exchange of electronic mail may be undesirable. It is simple for an application layer relay to distinguish the two types of traffic, much less so for relays in any of the lower layers.
The basic operation of an IP router is covered above. Since routers often operate in conjunction with LANs their performance is crucial. Some may support several interfaces simultaneously perhaps being connected to a couple of LANs and an X.25 network as well as a pointtopoint link to another router. The best routers can handle 10,000 packets a second. This requires considerable specialised hardware support since the perpacket processing can be quite high especially if fragmentation is necessary.
Two types of MAC bridge have been designed by IEEE with the object of interconnecting IEEE LANs of any types. Unfortunately, incompatibilities between the various MAC services make this difficult:
Therefore, generally bridges interconnect LANs of the same type.
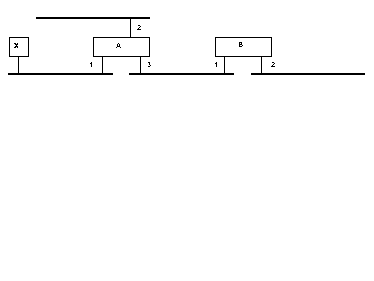 Figure 7. Transparent bridges
Figure 7. Transparent bridges
The design objectives here were that no manual configuration should be necessary the bridge should simply be attached to the two LANs and it should work. Also, host software should not need to be altered in any way. This is the usual bridge to use with Ethernets and token buses.
The bridge achieves this result by operating in "promiscuous mode"; i.e. it receives all frames whether or not they were addressed to it. It can then build up a routing table by "backward learning". Consider figure 8. If bridge B receives a frame with source address 'x' on interface '1' then it knows that interface '1' would be a good place to send any subsequent frames that have 'x' as their destination address. Of course, if it receives a frame with destination address 'x' through interface 1 it can ignore it as the frame is already on the right LAN. If a frame is received for which no routing table entry exists it will be flooded on all interfaces except the one it arrived on.
 Figure 8. Transparent bridge
- loops
Figure 8. Transparent bridge
- loops
A hash table is used to speed up the routing table search. If routes are not "refreshed" frequently by the receipt of an incoming frame they are timed out and relearnt. This allows the bridge to adapt to topology changes. A certain amount of intelligent filtering is both desirable and possible but this is more difficult than with a router due to the "flat" MAC address space.
The flooding algorithm causes problems if the topology contains loops as a bridge will eventually receive a flooded frame on two of its interfaces with resultant confusion. An algorithm which allows bridges to negotiate a "spanning tree" has been devised to cope with this problem. Figure 9 illustrates the problem to be solved. A frame from host X for an unknown destination will be flooded by both bridges A and C, and subsequently by B. Two copies will appear on LAN R. Bridges A and B will see this as a frame for an unknown destination and will forward the frame and so on.
The spanning tree algorithm overlays a spanning tree on the network and so prevents loops forming. It does this by effectively disabling some bridge interfaces. For example, in Figure 6 we might disable interface 3 on bridge A. This fixes the problem but at the expense of introducing sub-optimal routing and making load-sharing impossible.
This is the bridge usually used with the token ring. It requires bridges and hosts to learn the complete route to all possible destinations. This is in contrast to the transparent bridge which only learns the first hop of each route. It also requires host participation. These must at know whether the remote destination is or is not on their LAN. If it is not, the high order bit of the destination address is set to 1 so that the bridge will recognise it as special.
It is relatively simple to learn whether a destination is on the local LAN because token ring addresses are structured so that 12 bits are regarded as a LAN identifier. Each bridge has a 4-bit identifier which must be unique in the context of its LANs. Thus there may be two bridges with identifier 6 but these cannot have any LANs in common. Allocating bridge identifiers is the job of a human manager. Source routes consist of a sequence of bridge id, LAN id, bridge id, LAN id ... In Figure 9 a route from X to Y might be B3, L4, B4, L2, B2, L3.
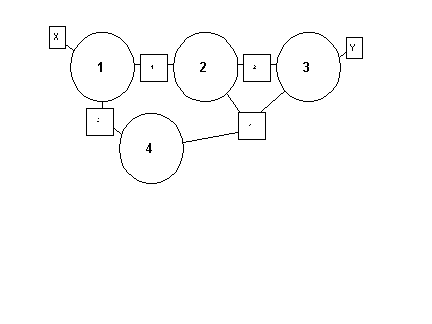 Figure 9. Linked Token Rings
Figure 9. Linked Token Rings
Bridges operate in promiscuous mode. On receipt of a frame they look for the "remote" bit in the header and, if this is set, they look at the source route. If they see they are on this route they will forward the frame on the next LAN, otherwise the frame will be dropped. For example, if bridge 4 receives a frame from LAN 4 with a source route as in the example above, it will forward it on LAN 2.