DARPA
Radioactive Project Year 1 Technical Report
Jon Crowcroft
and Peter Kirstein
Department of Computer Science, University College London
03 October 2000
Abstract
This is the first year report for the DARPA Radioactive Project, funded from July 1 1999.
We had previously implemented and demonstrated an Application Layer Active Network (ALAN) infrastructure, known as FunnelWeb. This infrastructure permits the dynamic deployment of active services in the network, but at the application level rather than the router level. With this technology, the advantages of active networking are realised, without the disadvantages of router level- implementation.
One infrastructure and three main areas of application service work were progressed during the year. On Infrastructure, we had previously left unsolved the issue of appropriate placement of ALAN supported services; this is an Application Layer Routing problem. In this report we define this problem and show that, in contrast to IP, it is a multi-metric problem. We then propose an architecture that helps conceptualise the problem and build solutions. We propose detailed approaches to the active node discovery and state maintenance aspects of Application Layer Routing (ALR). As Application services, we have built an ALAN layer caching architecture. On top of that, we have built an ALAN layer reliable multicast scheme. Finally, we are just starting on self-organisation algorithms for transcoding.
This report describes our progress in all these areas. It indicates also our plans for the next year of the project.
Abstract...................................................................................................................................................................... 1
1. Introduction and Background........................................................................................................................ 3
1.1. Introduction............................................................................................................................................. 3
1.2. Related
Work........................................................................................................................................... 3
1.3. Stated
Aims of RADIOACTIVE and our Progress............................................................................. 4
1.4. Organisation
of the Report.................................................................................................................... 4
2. The FunnelWeb Infrastructure...................................................................................................................... 5
2.1. Overview................................................................................................................................................... 5
2.2. The
Execution Environment for Proxylets........................................................................................... 5
2.3. Proxylets................................................................................................................................................... 5
2.4. Dynamic
Protocol Stacks....................................................................................................................... 6
2.5. Control
Architecture............................................................................................................................... 6
2.6. Security..................................................................................................................................................... 6
3. An Architecture for Application Layer
Routing......................................................................................... 6
3.1. Introduction............................................................................................................................................. 6
3.2. Application
Layer Active Networking................................................................................................. 7
3.3. Application
Layer Routing Architecture............................................................................................. 7
3.4. Discovery................................................................................................................................................. 8
3.4.1. Discovery phase............................................................................................................................. 8
3.4.2. Requirements.................................................................................................................................. 8
3.4.3. The discovery protocol................................................................................................................. 8
3.4.4. Messages exchanged by discovery
proxylet........................................................................... 10
3.5. Routing
exchanges................................................................................................................................ 11
3.5.1. Connectivity mesh....................................................................................................................... 11
3.5.2. Snooping on networking proxylets........................................................................................... 11
3.5.3. Self-Organising Application-level
Routing - SOAR............................................................... 12
3.6. Current
Status........................................................................................................................................ 13
4. Some Proxylets to Aid Multicast................................................................................................................. 13
4.1. Introduction........................................................................................................................................... 13
4.2. Multicasting........................................................................................................................................... 13
4.3. Distributed
Multicast Mechanisms.................................................................................................... 14
4.3.1. RLC................................................................................................................................................. 14
4.3.2. RMDP............................................................................................................................................. 15
4.4. Implementation...................................................................................................................................... 15
4.4.1. Overall Design.............................................................................................................................. 15
4.4.2. The Sender Side Proxylet............................................................................................................ 16
4.4.3. The Receiver Side Proxylet......................................................................................................... 16
4.5. Evaluation............................................................................................................................................... 17
5. The Webcache Proxylet and Other FunnelWeb
experiments................................................................. 17
5.1. Introduction........................................................................................................................................... 18
5.2. TCP
bridge.............................................................................................................................................. 19
5.3. VOIP
gateway........................................................................................................................................ 19
6. Activities During the Coming Year............................................................................................................. 20
7. The November PI Meeting........................................................................................................................... 20
7.1. Collaborative
Working Requirements................................................................................................ 20
7.2. The
Non-UCLActivities....................................................................................................................... 20
7.3. UCL
Activities....................................................................................................................................... 20
7.4. A
schematic of the Atlanta Demo....................................................................................................... 21
8. Staffing and Acknowledgements................................................................................................................ 21
8.1. Staffing.................................................................................................................................................... 21
8.2. Travel...................................................................................................................................................... 22
References................................................................................................................................................................ 22
1. Introduction and Background
1.1. Introduction
Active Networks can be observed as a novel
approach to networking that aims to permit user-defined computation within the
network. This architecture provides applications with a mechanism to load
protocol processing code into the network on demand. Traditional networks
suffer from problems of slow service evolution due to the inflexibility of the
existing infrastructure. Active Networks address the problems of integrating
new services and technologies; they strive to overcome the problems of poor
performance levels and to extend the functionality of the network
infrastructure.
If the user is empowered with ability to inject
custom programs into the network, then security is of major concern. The Active
Network architecture must provide a framework that allows services to be
expressed safely, easily and with minimum impact on other network users. The
architecture must be flexible enough to accommodate new services, and
restrictive enough to meet security and performance goals. We believe that the
ability to tune the network service to a particular application is a
justifiably important issue, if the security properties of network are
protected.
Much of the current work in Active Networks can
be classified into two main areas [tenn1]: the capsule method and the
programmable switch technique. The capsule method is based on the concept of
having service nodes to observe every packet that arrives at the node as being
part of a program. Each packet is interpreted as a fragment of a program that
contains embedded data. The service nodes evaluate each packet in turn, and
perform any necessary computations or modifications to the packet contents.
This approach is thought by many to be unrealistic, as it introduces
intolerable security and safety issues. The programmable switch technique is
based on a system that allows users to place customised programs into service
nodes, which can be loaded and executed on demand. The service nodes provide an
execution environment for running the customised programs, and also have the
capability to perform computations on the traffic passing through the node. The
user therefore has the flexibility to send their data through specific service
nodes for code processing.
There are a number of existing applications that
apply the concepts of active services in traditional networks. This class of
services includes firewalls (monitor and filter the traffic that comes in or
out of a network), web proxies (used to provide a user-transparent service
tailored to the serving and caching of web pages), video gateways, and nomadic
routers to name a few.
1.2. Related Work
Active Networks have been an important area of
research since the seminal paper by Tennenhouse [tenn2]. Our approach is
more oriented towards active services [fry2], [amir], which has emerged as an
important subtopic through the Openarch conference and related events. One
aspect of our current work, is to address problems associated with
self-organisation and routing, both internal to Active Services infrastructure,
as well as in support of specific user services. To this end we are taking a
similar approach to the work in scout [mont], specifically the joust
system [hart], rather than the more
adventurous, if less deterministic, approach evidenced in the Ants work [weth], [cald]. Extension of these ideas
into infrastructure services has been carried out in the MINC Project [minc]
and is part of the RTP framework (e.g. Perkins' work on RTP quality [rtpq]).
Much of the work to date in topology discovery
and routing in active service systems has been preliminary. We have tried to
draw on some of the more recent results from the traditional (non-active)
approaches to these two sub-problems; to this end, we have taken a close look
at work by Francis [yall], as well as
the nimrod project [nimrod]. Our approach is to try to provide self-organising
behaviour as in earlier work [kouv], [cald], [yead]; we believe that this is
attractive to the network operator as well as to the user.
There have been a number of recent advances in
the area of estimation of current network performance metrics to support end
system adaptation, as well as (possibly multi-path) route selection. For
example, for throughput, there is the work by Mathis [math], Padhye [padh] and Handley [hand], and for
multicast [rlc], and its application in
routing by Villamizar [vill]. More
recently, several topology discovery projects have refined their work in
estimating delays, and this was reported in Infocom this year, for example, in
Theilman [thei], Stemm [stem], Ozdemir
[ozd] and Duffield [duff].
1.3. Stated Aims of RADIOACTIVE and our Progress
In
our proposal, we proposed to investigate the following:
·
Policy Derivation
·
Application Level
Routing
·
Packet Forwarding
with DiffServ
·
Location of key
Modules
·
Algorithms for Forwarding
·
Security Architectures
·
PKIs
·
IPSEC/IKE
·
Depositories
·
Secure Conferencing
·
Security in Relays
·
QoS and Security
Policy Modules
·
Demonstration Applications
·
Measurement and Monitoring
·
Large-scale Control of Audio Devices
During the first 12
months, we expected to address problems in the following areas:
Work Package 1
·
Application Level
Routing, with multimetric criteria
·
Inter-domain
proxylet Services (including Receiver-driven Layered Congestion Control (RLC)
algorithms
·
Dynamic Reservation
Protocols
·
Object Location
Services
·
Security Services
·
Inter Domain
Proxylet Services
We expected to write a
report within the first 18 months on the architecture
Work Package 2
Here
we expected to provide a measurement framework, but only after 24 months
Work Package 3
Here we expected during
the first 12 months to develop relays for stream aggregation, filtering and
coding, and proxies that dealt with reliable multicast establishment.
In practice, we have
pursued our activities correlate closely with our intentions with one
exception. In the original proposal we were not sure whether another proposal
[crow2] on security technology would be funded. In the event that second
proposal was funded also, and the security activities were pursued in that
project. Much of the year has been spent in putting the ALAN infrastructure
into place, and developing the components, which we promised to provide. This
report describes what we have accomplished. We believe that we will be in an
excellent position to demonstrate our results in the next PI meeting in Georgia
Tech in November.
1.4. Organisation of the Report
This report is organised as follows. We first describe, in Section 2, our ALAN
infrastructure, FunnelWeb; we then show, in Section 3, how the infrastructure
is used for Application Layer Routing, and identify issues that require
solution. We then propose an architecture that aids conceptualisation and provides
a framework for an implementable solution.
This portion concentrates on the issues of node (EEP) discovery and
state maintenance. We conclude by
referencing related work and describing our future work, which is already in
progress.
In Section 4, we follow with a description of two multicast protocols: Receiver-driven Layered Congestion Control (RLC) and the Reliable Multicast Distributed Protocol (RMDP), and how they offer a scalable solution to the problems of reliability and congestion control in the global network. In Section 5, we describe our work in our most elaborate service - web caching., and some other Proxylet that we have developed. In Section 6 we discuss our plans for future work, and in Section 7mention what we propose to show at the November 2000 PI meeting. Finally, in Section 8, we provide some administrative details on the use of resources.
2. The FunnelWeb Infrastructure
2.1. Overview
The FunnelWeb system provides the user with a flexible framework for supporting active services within traditional network boundaries. The programming language used is Java, and the architecture consists of three main components: Execution Environment for Proxylets (EEPs), proxylets and dynamic protocol stacks.
The EEP is a service node that provides an execution environment for application level control modules, called proxylets. Proxylets can be dynamically loaded onto the EEP infrastructure, and they usually contain the code that performs the networking and filtering functions. It is possible to place proxylets on regular World-Wide Web [tberl] (WWW) servers, and to reference them by a Universal Resource Locator (URL). They may also be obtained from protocol servers. We discuss the workings of these components in the following sections.
2.2. The Execution Environment for Proxylets
Execution Environment for Proxylets (EEPs) are deployed on nodes throughout the network to perform special servicing functions. The EEP can await a set of requests (communicated via RMI) to load and execute proxylets on behalf of a third party. The set of requests that can be communicated to the EEP is defined below.
Load The load request is used to pass references for proxylets to the EEP, in order for the EEP to perform a number of acceptance checks on the referenced proxylet. This includes validation, loading, permission and security checks. If the proxylet is acceptable, then it is loaded onto the EEP and awaits the run request. As proxylets are loaded by URL reference, it is possible for the server to use a local WWW cache for references that have already been loaded.
Run: Once the proxylet has been loaded successfully, the server awaits a call to the RUN method, which provides the proxylet with a set of arguments. The arguments are used to specify hostnames, particular protocols or transcoders to be used or further downloaded.
Modify This request allows the state of a running proxylet to be changed.
Stop This request allows the server to force termination of a running proxylet.
The EEP is central to the workings of the FunnelWeb system, and it is envisaged that they will be deployed all over the global network. In a typical end-to-end communication path, one or more EEPs will be used as service points to enhance the performance and to provide services tailored to a specific application. Currently, the locations of our EEPs are known beforehand, as there are no dynamic EEP resolutions algorithms currently deployed. A mechanism is required to discover best placed EEPs across an end-to-end path distributed across the network. An approach similar to routing protocols is presently being developed that allows EEPs to be discovered dynamically.
2.3. Proxylets
Proxylets are control modules that contain the code for processing the necessary filtering and networking functions of a service. It is possible for proxylets to be self-contained units. However, the downloading of parts of required protocol stacks (dynamic protocol stacks) from Dynamic Protocol Servers encourages code sharing and reuse. The proxylets are executed on EEP machines, and highlights an important mechanism in the system for providing new services and enhancing end-to-end performance and utilisation.
The proxylet interface is implemented in a similar fashion to the way interfaces are implemented on applets running a WWW browser. The EEP machine executes the proxylets by invoking the methods of the proxylet interface: init(), run(), modify(), and stop(). Once a proxylet has been downloaded successfully, it is stored as a collection of class files bundled together in the form of a single Java archive. The Jar (Java archive) file is a collection of class files produced as a result of the Java compilation process. Each proxylet exists as one Jar file that is subsequently placed on a WWW server (or protocol server) so that it can be referenced via an URL. When The EEP receives a load call, it initialises the proxylet to be loaded by calling the init () method of the proxylet.
The sequence of events are described below:
1. The EEP loads the proxylet (Jar file) from a WWW server via an URL. The class files of the Jar file contain the machine independent byte codes for the requested proxylet, which are loaded by the Dynamic Proxy Server.
2. The EEP instantiates an instance of the proxylet object, and then calls the init() method of the proxylet class to initialise the downloaded proxylet.
3. The server invokes the proxylets’ run() method, which starts the execution of the proxylet. The run() method is where most of the code for networking and filtering is encapsulated and it is possible to supply arguments to this request.
4. When the server no longer needs the proxylet, it invokes the proxylets stop() method. It may be necessary to force termination of a proxylet, which may refuse to terminate naturally.
2.4. Dynamic Protocol Stacks
Communication systems require matching protocol stacks to enable entities to communicate and interoperate. In the FunnelWeb system, Dynamic Protocol Stacks have been designed to simplify the interoperability process, by allowing code for Dynamic protocol stacks to be written once and placed on repositories where they can be shared. These protocol stacks can then be downloaded onto either the end systems or the Execution Environment for Proxylets, so that end systems (or proxylets) can adopt the same stack.
2.5. Control Architecture
The FunnelWeb system provides a Control Interface for making explicit connections to a particular EEP. This interface uses Remote Method Invocation (RMI) to communicate with the remote EEP that we wish to run the proxylet on. It is also envisaged that specialised control interfaces will be developed to enable user interaction. To achieve this, the Monitor Interface has been developed, that allows the user to observe the execution of proxylets on a given EEP machine. The Monitor Interface will enable the user to take control over the running of proxylets on a EEP machine.
2.6. Security
Without suitable safeguards and security measures, the active network concept will remain unacceptably fragile. The security issues of the FunnelWeb system are continually being addressed. However, the application layer solution propose by the FunnelWeb system uses a control protocol that makes the situation slightly more tractable. It is quite clear that stringent restrictions have to be placed on the user, as they have the flexibility to execute arbitrary code on foreign machines. The FunnelWeb system has defined the following security rules in order to make the environment safe:
· Only trusted hosts are allowed to submit requests to an EEP
· EEPs cannot download proxylets from untrusted WWW servers.
· Verification checks are performed on proxylets to ensure that they are acceptable.
· EEP can only communicate with proxylets via the interface provided, thereby protecting the EEP from modifications.
The Java programming language itself also adds useful security features. The FunnelWeb system uses one such mechanism that allows one to add one's own security manager to the run-time system. This mechanism has been used to prevent proxylets from reading or modifying local files on the EEP machine. Ongoing work in this area aims to disallow certain local operations, and to relax the constraints on the originating source of the proxylet.
3. An Architecture for Application Layer Routing
3.1. Introduction
We have previously proposed, implemented and demonstrated an approach to active networks based on Application Layer Active Networking (FunnelWeb) [fry1]. We believe that this approach can achieve many of the benefits ascribed to active networks without the considerable drawbacks evident in the implementation of active networks in IP routers.
Our approach has been validated by developments in the commercial Internet environment. Some Internet Service Providers (ISPs) will support servers at their sites supplied by third parties, to run code of their (3rd parties') choice. Examples include repair heads [hang]. servers in the network, which help with reliable multicast in a number of ways. In the reliable multicast scenario an entity in the network can perform ACK aggregation and retransmission. Another example is Fast Forward Networks Broadcast Overlay Architecture [ffh]. In this scenario there are media bridges in the network. These are used in combination with RealAudio [real] or other multimedia streams to provide an application layer multicast overlay network.
At this time it is the case that “boxes” are being placed in the network to aid particular applications. The two applications that we have cited are reliable multicast and streaming multimedia delivery. There are other such boxes being placed inside ISP’s networks, to help with content delivery.
We believe that rather than placing “boxes” in the network to perform specific tasks, we should place generic boxes in the network that enable the dynamic execution of application level services. We have proposed an ALAN environment based on an Execution Environment for Proxylets (EEP). In our latest release of this system we rename the application layer active nodes of the network Execution Environments for Proxylets (EEPs). By injecting active elements known as proxylets on EEPs we have been able to enhance the performance of network applications.
In our initial work we have statically configured EEPs. This has not addressed the issue of appropriate location of application layer services. This is essentially an Application Layer Routing (ALR) problem.
For large-scale deployment of EEPs it will be necessary to have EEPs dynamically join a mesh of EEPs, with little to no configuration. As well as EEPs dynamically discovering each other applications that want to discover and use EEPs should also be able to choose appropriate EEPs as a function of one or more form of routing metric. Thus the ALR problem resolves to an issue of overlaid, multi-metric routing.
3.2. Application Layer Active Networking
Our infrastructure is quite simple and is composed of two components. Firstly we have a proxylet. A proxylet is analogous to an applet or a servlet. An applet runs in a WWW browser and a servlet runs on a WWW server. In our model a proxylet is a piece of code which runs in the network. The second component of our system is an (Execution Environment for Proxylets) EEP. The code for a proxylet resides on a WWW server. In order to run a proxylet a reference is passed to an EEP in the form of a URL and the EEP downloads the code and runs it. The process is slightly more involved but this is sufficient detail for the current explanation.
In our initial prototype system ``FunnelWeb'', the EEP and the proxylets are written in Java. Writing in Java has given us both code portability as well as the security of the sandbox model. The FunnelWeb package has been run on Linux, FreeBSD, Solaris and NT.
3.3. Application Layer Routing Architecture
Several routing requirements for our FunnelWeb infrastructure have emerged from the examples described in the previous section. In essence our broad goal is to allow clients to choose an EEP or set of EEPs on which to run proxylets based on one or more cost functions. Typical metrics will include:
· available network bandwidth
· current delay
· EEP resources
· topological proximity.
We may also want to add other constraints such as user preferences, policy, pricing, etc. In this paper we focus initially on metric-based routing.
An Application Layer Routing (ALR) solution must scale to a large, global EEP routing mesh. It must permit EEPs to discover other EEPs, and to maintain a notion of “distance” between each EEP in a dynamic and scalable manner. It will allow clients to launch proxylets (or “services”) based on one or more metric specifications and possibly other resource contingencies. Once these services are launched, they become the entities that perform the actual “routing” of information streams.
We therefore propose an ALR architecture that has four components. In this section we simply provide an overview of the architecture. The four components are as follows.
· EEP Discovery
· Routing Exchanges
· Service Creation
· Information Routing
EEP discovery is the process whereby an EEP discovers (or is able to discover) the existence of all other EEPs in the global mesh. In our current implementation (described below) all EEPs register at a single point in the network. This solution is clearly not scalable, requiring the introduction of a notion of hierarchy. Our proposed approach is described in the next section. The approach addresses both the arrival of new EEPs and the termination or failure of existing EEPs.
Routing exchanges are the processes whereby EEPs learn the current state of the FunnelWeb infrastructure with regard to the various metrics. On this basis EEP Routing Tables are built and maintained. The routing meshes embedded in routing tables may also implement notions of clusters and hierarchy. However these structures will be dynamic, depending on the state of the network, with different structures for different metrics. The state information exchanges from which routing information is derived may be explicitly transmitted between EEPs, or may be inferred from the observation of information streams.
Service creation is the process whereby a proxylet or set of proxylets are deployed and executed on one or more EEP. The client of this service creation service specifies the proxylets to be launched and the choice(s) of EEP specified via metrics. The client may also specify certain service dependencies such as EEP resource requirements.
The service proxylets to be launched depend entirely on the service being provided. They encompass all the examples described in the previous section. For example, the webcache proxylet launches transcoders or compressors according to mime content type. The metric used here will be some proximity constraint (e.g. delay) to the data source, and/or available bandwidth on the path. The TCP bridge proxylets will be launched to optimise responsiveness to loss and maximise throughput. The VOIP gateway proxylet will require a telephony gateway resource at the EEP.
Information routing is the task performed by the proxylets once launched. Again the function performed by these proxylets are dependent on the service. It may entail information transcoding, compression, TCP bridging or multicast splitting. In each case information is forwarded to the next point(s) in an application level path. The next subsection provides our more detailed proposals for EEP Discovery and Routing Exchanges.
3.4. Discovery
3.4.1. Discovery phase
We will now describe how the discovery phase takes place. The function of the discovery phase is for all EEPs to join a global “database”, which can be used/interrogated by routing proxylets or perhaps other proxylets.
A possible solution is that any EEP, which is started, should join a mesh of all running EEPs. This “database” can then be interrogated to find the location of an EEP, which satisfies the appropriate constraints.
To provide a totally flexible infrastructure the problem can be solved in a number of stages. The two main stages are a distributed discovery and a registration phase. In the first, all that takes place is discovery; in the second, all the EEPs register their existence. This ``database'' can then be used by other services to build a routing infrastructure.
3.4.2. Requirements
There are a number of requirements for our discovery phase:
1. The solution should be self-configuring. There should be no special configuration such as tunnels between EEPs.
2. The solution should be fault tolerant.
3. The solution should scale to hundreds or perhaps thousands of deployed EEPs.
4. No reliance on technologies such as Multicast.
5. The solution should be flexible.
3.4.3. The discovery protocol
The solution involves building a large distributed database of all nodes. We will walk through an EEP starting up in order to provide an overview of the process. The discovery process builds a hierarchy of EEPs.
When an EEP first starts up it will start a discovery proxylet. The discovery proxylet is responsible for an EEP joining the global mesh. The discovery proxylet will contain a list of EEPs with which it should register. The list will either be pre-configured or will be have been stored by a previous invocation of the EEP. The list will be traversed until a registration succeeds. A registration will be considered to have succeeded when an acknowledgement is returned by the EEP with which it has tried to register. The acknowledgement will contain a timer value to denote when this EEP should next send a registration message. The acknowledgement will also carry a list of EEPs to register with in the future. The EEP should save this list to stable storage. When an EEP is run for the first time it will attempt to register with a node which is at the top of a hierarchy. This top level EEP will typically respond with an acknowledgement which contains a new list of EEPs to register with someway down the hierarchy.
A list of EEPs is returned in the acknowledgement in order to provide a level of fault tolerance. The list is only traversed if a previous EEP does not respond. All EEPs will be pre-configured with the location of a root node, we could actually have a number of co-operating root EEPs, for simplicity we will consider a single root EEP.
The first time an EEP is started the discovery proxylet will register with the root EEP. The root EEP will respond with a list of EEPs typically the root EEP will redirect the registering EEP, such that it registers further down the hierarchy. The last element in the list will typically be the root. So if all other EEPs fail the EEP will again register with the root EEP.
A naive registration/discovery model might have all registrations always going to one known location. The scheme we have described does potentially fall back to this model. However if all registrations always go through one point then this root EEP will hold state about all EEPs as well as having to service all requests for the list of EEPs. If there were for example one million EEPs registering with one root EEP, then an Ack/registration implosion may form towards the root EEP. As bad or perhaps worse, only the root EEP will hold the knowledge of the state of the EEPs. If the list of EEPs needs to be extracted, with one million EEPs and four-byte IPv4 addresses then four million bytes of data will be moved. This is a very conservative estimate of the number of potential bytes transferred. Conversely the root EEP may be asked to send a message to all the EEPs that it is aware of, best case this would involve sending a million packets, which could take a while.
In order to spread the load we have opted for a model where there is a hierarchy. Initially registrations may go to the root EEP, but it returns a new list of EEPs with whom to register – thus building up a hierarchy. An EEP has knowledge of any EEPs, which have registered with it, as well as a pointer to the EEP above it in the hierarchy. Thus the information regarding all the EEPs is distributed as well as distributing where the registration messages go. The time to send the next registration message is also included in the protocol. As the number of EEPs grows or as the system stabilises the frequency of the messages can be decreased. If an EEP that is being registered with fails then the EEP registering with it will just try the next EEP in its list until it gets back to the root EEP.
With this hierarchical model, if the list of all EEPs is required then an application (normally this will be only routing proxylets), can contact any EEP and send it a node request message. In response to a node request message number three chunks of information will be returned: a pointer up the hierarchy where this EEP last registered; a list of EEPs that have registered with this EEP if any; a list of the backup EEPs that this EEP might register with. Using the node message interface it is possible to walk the whole hierarchy. So either an application extracts the whole table and starts routing proxylets on all nodes. Or a routing proxylet is injected into the hierarchy, which replicates itself using the node message.
The discovery proxylet offers one more service. It is possible to register with the discovery proxylet to discover state changes. The state changes that are of interest are the following: a change in where registration messages are going; an EEP which has failed to re-register and is being timed out; a new EEP joining the hierarchy.
In the discussion above we have not said anything about how the hierarchy is actually constructed. We do not believe that it actually matters as long as we have distributed the load, to give us load balancing and fault tolerance. It may seem intuitive that the hierarchy is constructed around some metric such as RTT. So say all EEPs in the UK register with an EEP in the UK. This would certainly reduce the number of packets exchanged against a model that had all the registrations made by EEPs in the UK going to Australia. A defence against pathological hierarchies is that the registration time can be measured in minutes or hours not seconds. We can afford such long registration times because we expect the routing proxylets to exchange messages at a much higher frequency and form hierarchies based on RTT and bandwidth etc. So a failed node will be discovered rapidly by the routing level. Although it seems like a chicken and egg situation the discovery proxylets could request topology information from the routing proxylets. To aid in the selection of where a new EEP should register. We also do not want to repeat the message exchanges that will go on in the higher level routing exchanges.
We have been considering two other mechanisms for forming hierarchies. One is the random method. In this scheme a node will only allow a small fixed number of nodes to register with it. Once this number is exceeded any registration attempts will be passed of to one the list of nodes, which is currently registered with the node. The selection can be made randomly. If for example the limit is configured to be five as soon as the sixth registration request comes in the response will select one of the already registered nodes as the new parent EEP to register with. This solution will obviously form odd hierarchies in the sense that they do not map onto the topology of the network. It could however be argued that this method might give an added level of fault tolerance.
The second method that we have been considering is a hierarchy based on domain names; here the hierarchy maps directly onto the DNS hierarchy. So all sites with the domain ``.edu.au'' register with the same node. In this case we can use proximity information derived from the DNS to build the hierarchy. This scheme will however fail with the domain ``.com'', where nothing can be implied about location. The node that is accepting registrations for the ``.com'' domain will be overwhelmed.
So we believe that we can choose a hierarchy forming mechanism which is independent of the underlying topology. As registration exchanges will occur relatively infrequently. The more frequent routing exchanges discussed in the next section will map onto the topology of the network and catch any node failures.
We have discussed a hierarchy with a single root. If this proved to be a problem, then we could have an infrastructure with multiple roots, but unlike the rest of the hierarchy the root nodes would have to be aware of each other through static configuration. As they would have to pool information in order to behave like a single root.
3.4.4. Messages exchanged by discovery proxylet
There are just two types of messages used. The registration messages and the node messages. The registration messages are used solely to build the hierarchy. The node messages are used to interrogate the discovery infrastructure.
The version numbers are interesting in that not only can they be used to detect a protocol mismatch, they can be used to trigger the updating on a proxylet.
The host count will make it simple to discover the total number of nodes by just interrogating the root node.
At this time we have not decided how the messages should be carried. We have experimented with a combination of UDP and Java RMI.
·
Registration
request message
· Version number
· This nodes name
· Count of hosts registered below this node
· Registration acknowledgement message. Sent in response to a registration request message.
· Version number
· Next registration time. A delay time before the next registration message should be sent. This timer can be adjusted dynamically as a function of load, or reliability of a node. If a node has many children the timer may have to be increased to allow this node to service a large number of requests. If a child node has never failed to register in the required time, then it may be safe to increase the timeout value.
· List of nodes to register with A used for fault tolerance. Typically the last entry in the list will be the root node.
·
Node request
message
· Version number.
· Node acknowledgement message These are sent in response to a node request message.
· Version number
· Host this node registers with
· List of backup nodes to register with. It is useful to have the list of backup nodes in case the pointer up to the local node fails, while a tree walk is taking place.
· List of nodes that register with this node
3.5. Routing exchanges
Once the underlying registration infrastructure is running this information can be used to start routing proxylets on the nodes. The process is simple and elegant. A routing proxylet can be loaded on any EEP. One routing proxylet needs to be started on just one EEP anywhere in the hierarchy. By interrogating the discovery proxylet all the children can be found as well as the pointers up the tree. The routing proxylet then just starts an instance of itself on every child and on its parent. This process repeats and a routing proxylet will be running on every EEP. The routing proxylet will also register with the discovery proxylet to be informed of changes (new nodes, nodes disappearing, change in parent node). So once a routing proxylet has launched itself across the network, it can track changes in the network.
Different routing proxylets can be written to address the various problems. Probably one of the most important routing proxylets will be one that can give proximity information. An example is to find the closest EEP to particular IP address. This problem could be solved in a number of possible ways. A simple naive mechanism would match DNS names, looking for a longest prefix match. Another way would be to do a longest IP prefix match. This may actually work well in the future when more of the world is using CIDR [rek]. In fact with IPv6 addressing this scheme may work perfectly.
It may not even be necessary run a routing proxylet on each node. It may be possible to build up a model of the connectivity of the EEP mesh by running short-lived probing proxylets only occasionally on each cluster.
The boundary between having a totally centralised routing infrastructure against a totally distributed routing infrastructure can be shifted as appropriate.
We believe that many different routing proxylets will be running using different metrics for forming topologies. Obvious examples would be paths optimised for low latency or for high bandwidth.
3.5.1. Connectivity mesh
In the ALR section we described a number of proxylets that we have already built or are under consideration. Along with their requirements from an ALR, a lot of the routing decision can be solved satisfactorily, by using simple heuristics such as domain name. There will, however, be a set of proxylets, which require more accurate feedback from the routing system.
We believe that some of the more complex routing proxylets will have to make routing exchanges along the lines of map distribution MD [nimrod]. A MD algorithm floods information about local connectivity to the whole network. With this information topology applications can be constructed. Routing computations can be made hop-by-hop; an example might be an algorithm to compute the highest bandwidth pipe between two points in the network. A more centralised approach may be required for application layer multicast where optimal fan-out points are required.
In traditional routing architectures, each node by some mechanism propagates some information about itself and physically connected neighbours. Metrics such as bandwidth or RTT for these links will also be included in these exchanges. In the ALR world we are not constrained by using only physical links to denote neighbours. There may be conditions where nodes on opposite side on the world may be considered neighbours. Also links do not necessarily need to be bi-directional. We expect to use various metrics for selecting routing neighbours, such as RTT or bandwidth. So in order to support multimetric routing we will not necessarily be distributing multiple metrics through one routing mesh. We may create a separate routing mesh for each metric.
Another important issue, which does not usually arise from traditional routing, is that if care is not taken, certain nodes may disappear from the routing cloud if a node cannot find a neighbour.
3.5.2. Snooping on networking proxylets
Proxylets started on EEP make use of standard APIs in order to make networking calls. It would be relatively simple to add a little shim layer whenever a networking call is made in order to estimate the bandwidth of a path as described in the next section. So bandwidth information derived from proxylets can be fed back into the routing infrastructure as described in the next section.
3.5.3. Self-Organising Application-level Routing - SOAR
We propose a recursive approach to this, based on extending ideas from RLC [rlc] and SOT [kouv], called Self-Organised Application-level Routing (SOAR). The idea is that a SOAR does three tasks:
1. Exchanges graphs/maps [nimrod] [fran1] with other SOARs in a region use traffic measurement to infer costs for edges in graphs re-define regions.
A region (and there are multiple sets of regions, one per metric), is informally defined as a set of Soars with comparable edge costs between them, and "significantly" different edge costs out of the region. An election procedure is run within a region to determine which SOAR reports the region graph to neighbour regions. Clearly, the bootstrap region is a single SOAR.
The definition of "significant" above needs exploring. An initial idea is to use the same approach as RLC [rlc] - RLC uses a set of data rates distributed exponentially - typically, say, 10 Kbps, 56 Kbps, 256 Kbps, 1.5 Mbps, 45 Mbps and so on.
This roughly corresponds to the link rates seen at the edge of the net, and thus to a set of users possible shares of the net at the next "level up". Fine-tuning may be possible later.
2. SOAR uses measurement of user traffic (as in SOT [kouv]) to determine the available capacity - either RTCP reports of explicit rate, or inferring the available rate by modelling a link and other traffic with the Padhye [padh] equation provide ways to extract this easily. Similarly, RTTs can be estimated from measurement or reports (or an NTP proxylet could be constructed fairly easily). This idea is an extension of the notion proposed by Villamazar [vill] using the Mathis TCP simplification, in "OSPF Optimised Multipath", p < (MSS/(BWW * RTT)3)
A more complex version of this was derived by Padhye [padh]:
B = Min((Wm/RTT),
1/(RTT*SQRT(3bp/3)+To Min(1,3*SQRT(3bp/8) p(1+ 32 p 3))
|
Wm ; |
Maximum advertised receive window |
|
RTT ; |
The Round Trip Time |
|
b
; |
the number of packets acknowledged by 1
ACK |
|
p
; |
the mean packet loss probability |
|
B
; |
the throughput achieved by a TCP
flow |
Terms in the Padhye TCP Equation
RTT is estimated in the usual way, if there is two-way traffic,
Mean RTTi = RTTi
* alpha + (1-alpha) * RTT(I-1)
It can also be derived using NTP exchanges. Then we simply measure loss probability (p) with an EWMA. The Smoothing parameters (alpha, beta for RTT, and loss averaging period for p) need to be researched accurately - note that a lot of applications use this equation directly now [reja] rather than AIMD sending a la TCP. This means that the available capacity (after you subtract fixed rate applications like VOIP) is well modelled by this.
Once a SOAR has established a metric to its bootstrap-configured neighbour, it can declare whether that neighbour is in its region, or in a different region. As this continues, clusters will form; the neighbour will report its set of "neighbour" SOARs (as in a distance-vector algorithm) together with their metrics. Strictly we do not need the metrics if we are assuming all the SOARs in a region are similar, but there are lots of administrative reasons we may - in any case, a capacity-based region will not necessarily be congruent with a delay-based region. Also, it may be useful to use the neighbour exchanges as part of the RTT measurement.
The exchanges are of region graphs or maps - each SOAR on its own forms a region and its report is basically like a link state report. We will explore whether the SOAR reports should be flooded within a region, or accumulated as with a distance vector.
A graph is a flattened list of node addresses/labels, with a list of edges for each node, each with one or more metrics.
Node and Edge Labels are in a URL-like syntax, for example soar://node-id.region-id.soar-id.net and an Edge label is just the far end node label.
Metrics are <type, value> tuples (ASCII syntax). Examples of metrics include:
· A metric for delay is typically milliseconds
· A metric for throughput is Kbps
· A metric for topological distance is hop count
· A metric for topological neighbour is IP address/mask - more about this
As stated above, a SOAR will from time to time discover that a neighbour SOAR is in a different region. At this point, it marks itself as the "edge" of a region for that metric. This is an opportunity for scaling - the SOARs in a region use an election procedure to determine which of them will act on behalf of the region. The elected SOAR (chosen by lowest IP address, or perhaps at the Steiner centre, or maybe by configuration), then pre-fixes the labels with a region id (perhaps made up from date/time and elected SOAR node label.
soar://node-id.region-id.soar-id.net/metricname
soar://node-id.region-id.region-id.soar-id.net/metricname
soar://node-id.region-id.region-id.region-id.soar-id.net/metricname
Etc
3.6. Current Status
We have a prototype system ``FunnelWeb 2.0.1'' [fry3], which support the running of proxylets. We are running EEPs at a number of Universities in the UK as well as at UTS. We have a very basic combined discovery and routing proxylet, which supports the notion of close. So a DNS name can be given to the routing code and an EEP close to the name will be returned. The first cut at this problem just matches on DNS names. This very crude approximation works surprisingly well. We have a test page at <URL:http://dmir.socs.uts.edu.au/projects/alpine/routing/index.html>.
One of the very nice features of writing the discovery and routing entities as proxylets has been that we can totally redeploy the whole infrastructure in a very short time. As in most protocols we carry version information in our discovery exchanges. Unlike most protocols if a newer version of the protocol is detected the node with the older version of the protocol reloads itself with the newer version of the protocol. The upside is that there are no backward compatibility issues. The downside is that it is trivial to make the whole discovery mechanism fail.
We are in the process of rewriting our web cache proxylet [fry2], to make use of the routing infrastructure. An implementation of the RTT and bandwidth estimators for SOAR is underway.
4. Some Proxylets to Aid Multicast
4.1. Introduction
Active Networks permit applications to dynamically load custom programs in order to perform desired operations on user traffic. This innovative approach to networking offers a tractable solution to achieving end-to-end performance improvements, and allows protocols and services to be deployed rapidly. In this section we discuss how we can use the FunnelWeb system to provide multicast services for distributed applications. We provide a brief technical description of the Receiver-driven Layered Congestion Control (RLC) protocol and the Reliable Multicast data Distribution Protocol (RMDP) that we implemented, and demonstrate the deployment of these protocols within the FunnelWeb active services infrastructure.
4.2. Multicasting
Traditional network computing applications involve communication between two computers. They provide a point-to-point, unicast service with two well-defined connection endpoints. Unicast communications are used to serve many, if not most of today’s communication needs. However, there are many important applications, which require another model for communication. A large number of emerging applications require a model that encompasses simultaneous communication between groups of computers. These applications require a point-to-multiunit service of communication.
When a computer wishes to send data to many receivers simultaneously, it may follow one of two options [crow1]: it may repeatedly transmit the data to each individual receiver or use a technique called broadcast. Repeated transmissions suffer from scaling difficulties for large groups, and can be costly in terms of the network bandwidth required as the same information has to be distributed multiple times. The broadcast approach allows applications to send one copy of data to a broadcast address. This method allows the network to stop broadcasts at network boundaries or to send the message everywhere. Clearly, it can be seen that the latter option signifies a significant usage of network resources, especially when the size of the group of receivers is small.
The Internet offers an alternative solution to the point-to-multipoint problem. IP Multicasting provides the Internet with an attractive approach that saves precious bandwidth for point-to-multipoint data distribution. Multicasting allows applications to send one copy of each packet, to an address that represents a group of computers that wish to receive the data. In this way, data can be distributed to the hosts that have explicitly expressed an interest in receiving the data for that multicast group. This vision of point-to-multipoint communication relies on the network to forward packets to the relevant networks that wish to receive them, and to stop any others from receiving the data.
The Mbone [kum] (multicast backbone) is the multicast experimental infrastructure that has been developed to support network level multicast. The forwarding of multicast data in the Mbone is implemented with hosts using a group membership protocol known as the Internet Group Management Protocol (IGMP) [fenn]. Unlike unicast addresses for point-to-point communication, hosts can dynamically subscribe to multicast addresses and by doing so cause multicast traffic to be delivered to them. Multicast data is unlike unicast data in that the sending entity for multicast has to send the traffic to a special multicast group address. The receiver may then receive this data by using IGMP to tell its local router that it wishes to receive packets addressed for the multicast group address. This is called the join phase, and once a receiver has joined a group, the router enables the packets to be forwarded to that receiver. Likewise, receivers may choose to leave a group, and do so by informing the local router that they are no longer interested in receiving data from the group address. This is called the leave phase, and the router proceeds to cease the delivery of packets to that receiver.
In order to support the demands of emerging multicast applications, it is important for us to build networks, which can rapidly adapt to these requirements and provide efficient multicast services. Active Network technology is one such approach that allow us to enhance the performance and utilisation problems encountered by multicast applications. For example, today's Mbone is unable to accommodate and satisfy the diverged requirements of a set of multicast receivers. However, Active Networks permit the application to achieve optimal data rates, by specifying the network to take into account factors such as data rates, data formats, network access speed, and end-system performance.
In fact there has been a seeming failure to deploy multicast broadly in the wide area. It even starts to make sense to use proxylets inside the network to perform fan-out of streams, as well as perhaps transcoding and retransmission. A requirement that emerges for multicast is that there is enough information in the routing infrastructure for the optimal placement of fan-out points. In this section, we consider providing some of the more basic multicast elements by Proxylet techniques.
4.3. Distributed Multicast Mechanisms
Because of the difficulties associated with scalable multicast protocols, they are only a few working implementations of scalable multicast solutions to the problems of reliability and congestion control. However, none of these implementations have been accepted universally. In this section, we introduce two multicast protocols that offer solutions to these problems; both run with the FunnelWeb proxylet infrastructure. The first protocol is a useful congestion avoidance protocol for multicast applications, and is called the Receiver-driven Layered Congestion Control Protocol (RLC). Our second protocol, Reliable Multicast data Distribution Protocol (RMDP), is a reliable multicast transfer protocol that is used in conjunction with RLC to achieve TCP-like control congestion control. Both protocols were developed by L.Rizzo and L.Vicisano [riz1], [riz2].
4.3.1. RLC
The Receiver-driven Layered Congestion-control (RLC) algorithm provides us with a useful building block for providing point-to-multi-point congestion control for multicast applications. The protocol is based on a receiver-driven layered congestion-control algorithm, which is TCP-friendly and suitable for data transfer over an IP multicast service such as the MBone. It uses a layered organisation of data to support variable transmission rates, and provides the receivers with the flexibility to join one or more multicast groups, in order to adapt to the available network bandwidth. This gives the receivers the flexibility to make decisions autonomously.
RLC uses intelligent techniques for synchronisation, to control congestion levels behind shared bottlenecks. These techniques work by ensuring effective co-operation between receivers that share a given bottleneck. Full-scalability is achieved by keeping the sender side free of any feedback mechanisms, and by ensuring the receivers don't use explicit forms of group membership.
4.3.2. RMDP
RMDP is a scalable multicast protocol that supports the reliable distribution of data to a set of receivers. The version of RMDP defined in this paper is used in conjunction with the RLC multicast congestion control protocol defined above. RMDP aims to overcome the difficulties in ensuring reliable data delivery to large groups and adaptability of heterogeneous clients in reliable data transfers. RMDP achieves reliability by using Forward Error Correction (FEC) techniques, a redundant data encoding mechanism that is inherently tolerant to packet losses. The protocol controls congestion by adopting an efficient TCP-like congestion avoidance algorithm to accommodate individual multicast receiver rates.
4.4. Implementation
4.4.1. Overall Design
The integration of the RLC and the RMDP protocols with the active network has been done using similar implementations. The desire was to provide a transparent service, avoiding any radical changes to the natural workings of web servers and browsers. The reality of security has placed a profound effect on the design and interaction of proxylets with EEP. For reasonable security reasons, common support for servlets was discouraged. One consequence of this limitation was that the server side had to be deployed as a proxylet. One possible solution would be to deploy the client side as a plug-in (or applet). However, a better approach seemed entirely reasonable, if both the client and the server sides were both implemented as proxylets. In this way, we could then have the users configure their browsers to point at the appropriate proxy server, a local EEP machine.
The process of development used in this implementation proceeds in three phases. The first phase was concerned with the way the objects were to communicate, and where there would be located. From this, we deduced reasonable interfaces, and methods of communication, which enabled us to design the component proxylets. This included modifying existing code for RLC and RMDP, and implementing, deploying and testing them as proxylets.
The second phase was to further decide on exact locations of the objects and communication methods. We decided on the arguments, and at this stage, it was necessary to develop tools for analysis and testing. We used a simple program to inspect the data being transmitted to a multicast group address, and developed a simple applet to represent an application requiring multicast data. Proxylet Design
In this section, we aim to describe the workings of the sender and receiver side proxylets for RMDP. The version of RMDP used incorporates the functionality of RLC. We defined a simplified model of communication, which achieves an effective method of communication between the objects.
We chose to implement separate proxylets for the client and the server sides of communication, to achieve a simple and effective approach that avoids any unnecessary modifications to web servers and web browsers.
A diagram demonstrating the proposed model of communication is shown in Figure 1.
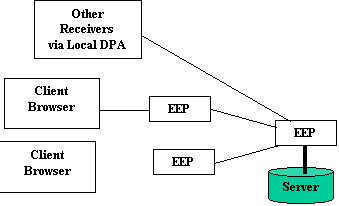
![]() Figure 1: FunnelWeb model of multicast
communication.
Figure 1: FunnelWeb model of multicast
communication.
The model above aims to provide a WWW transparent multicast service using the FunnelWeb proxylet system. Each EEP running a proxylet for a particular operation. For example, the EEP near the server would run the sender proxylet, and the other EEPs (for the clients) would be running the receiver side proxylets. These proxylets are discussed further in the following sections.
4.4.2. The Sender Side Proxylet
The sender side proxylet can be defined as the point of the “point-to-multipoint’’ method of multicast communication. Our implementation was fairly simple, and represents a transmitter that sends packets to a group multicast address, as soon as it receives a request from the first receiver. This transmission is continued until there are no more active receivers. This is unlike the continuous stream of data approach used by RLC. This is because an effort is made to achieve maximum quality for the available bandwidth.
Our vision for component interaction was kept simple, and is shown in Figure 2.
Response Request Request
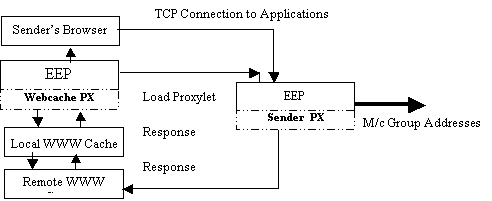
Figure 2: Object Communication with Sender side Proxylet
The sender side proxylet needs to be provided with the necessary arguments (number of layers, base port/multicast address, time-to-live field and inter-packet time) for proxylet that performs the particular operation. This is achieved with the aid of the webcache proxylet. The webcache proxylet will in the future load proxylets onto strategically located EEP machines. However, in order to make use of the webcache proxylet transparency mechanism, the user first needs to configure the proxy variable of its browser, to be directed at a local EEP machine running the webcache proxylet. This allows the webcache proxylet to observe all HTTP requests made by the browser transparently.
When the user makes a request to a WWW server, the server responds with the requested page preceded by a mime content type. The webcache proxylet has a table of mime content types of which it may perform special operations on. When the webcache proxylet identifies the content type for performing RLC/RMDP sender side operations, it responds by loading the sender side proxylet on a suitable EEP machine near the WWW server. Ongoing work is being done in this area, and as of yet this dynamic component has not been integrated with the webcache proxylet. In the current version, the location of EEP machines is known beforehand.
However, once an appropriate EEP has been located by the webcache proxylet, it loads the sender side proxylet onto the identified EEP machine. If this is successful, the sender side proxylet awaits a TCP connection from the remote browser. This is made possible by the intermediary webcache proxylet, as it is able to send a URL redirect to the browser, in order to load the necessary applet representing the application. One consequence of this approach is the restriction on applets, that they can only open connections to the host from which they were downloaded. This imposes the restriction that the applet has to be downloaded from the ”dynamically discovered” EEP machine which runs the sender side proxylet. However, this approach provides us with a mechanism for passing arguments and receiving data packets from the EEP machine. When the TCP connection arrives from the user's browser, the EEP machine running the sender side proxylet is able to pass the transmitted packets to the application if required
4.4.3. The Receiver Side Proxylet
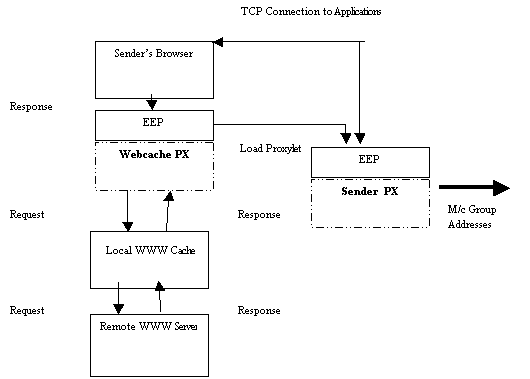 The
components of the receiver side proxylet inter-operate in a similar fashion to
that of the sender side proxylet. Here, when the receiver makes a HTTP request
for a WWW page, the webcache proxylet identifies the mime content type returned
by the WWW server, and proceeds to load the receiver side proxylet on an EEP
machine close to the receiver's browser. The webcache proxylet also sends a URL
redirect to the browser to load the page that contains the application. In our
case, we have developed a simple applet, that makes a TCP connection to the
local EEP machine running the receiver side proxylet. The EEP machine awaits
this connection on a specified port, and responds by streaming the multicast
data packets to the user's browser. Figure 3 shows the interaction between the
various components.
The
components of the receiver side proxylet inter-operate in a similar fashion to
that of the sender side proxylet. Here, when the receiver makes a HTTP request
for a WWW page, the webcache proxylet identifies the mime content type returned
by the WWW server, and proceeds to load the receiver side proxylet on an EEP
machine close to the receiver's browser. The webcache proxylet also sends a URL
redirect to the browser to load the page that contains the application. In our
case, we have developed a simple applet, that makes a TCP connection to the
local EEP machine running the receiver side proxylet. The EEP machine awaits
this connection on a specified port, and responds by streaming the multicast
data packets to the user's browser. Figure 3 shows the interaction between the
various components.
Figure 3: Object interaction for receiver side proxylet.
4.5. Evaluation
We have successfully implemented the RLC and RMDP scalable multicast protocols with the FunnelWeb system. The protocols were written in Java, which is the language used in the FunnelWeb network environment. One of the advantages of using this system was the ease at which applications could be written, deployed and executed within this environment. Another advantage of this system is the period of deployment. The deployment time of the proxylets was very short, and simply required the compilation of the package of classes into a Jar file, and placing it on a WWW server.
We chose to implement separate proxylets for the client and the server sides of communication, as this represents a simple and effective approach that avoids any unnecessary modifications to web servers and web browsers.
The final phase was to integrate the proxylets with the web transparently. This involved determining a suitable method of communication between the webcache proxylet and the RLC/RMDP proxylets. The webcache proxylet was key to the vision of transparency to both server and browser, and is discussed further in the next section.
5. The Webcache Proxylet and Other FunnelWeb experiments
The webcache proxylet provides us with a scheme that allows us to be transparently in the path of HTTP requests. This is achieved by configuring the proxy variable on the user's browser to the EEP machine that is running the webcache proxylet. This makes it possible for the webcache proxylet to observe the content types of the browser requests, and compare them with its table of mime content types on which it is able to perform special operations. The webcache proxylet may then add value to the content types that it has stored in its table entries. Otherwise, it simply relays the request to the real local WWW cache machine. For example, if we wanted to perform special processing on ``audio/basic'' content types, we would store this as an entry in the webcache proxylet table of mime content types. Then, when the webcache proxylet observes that the content type being returned is of this type, it is in a position to identify a nearby EEP machine. In the current version of the webcache proxylet, there is prior knowledge of the location of EEP. However, there is ongoing work in this area, in able to support dynamic EEP location discovery.
5.1. Introduction
In the past we have written a number of proxylets to test out our ideas. Possibly the most complicated example has been a webcache proxylet [fry2]. In this example we have a webcache proxylet which is co-resident with a squid cache. WWW browsers typically support a configuration option, which allows all accesses to go via a cache. A WWW browser could be pointed at our cache. The webcache proxylet does not actually perform any caching it relies on the co-resident cache to provide the caching. However as a function of the mime content type of a requested URL, it can perform transcoding or compression.
For example for large text files it might make sense to compress the file before it is transmitted. Although this might be a useful transform to perform it would require every WWW server that we may access to have a special modification to support compression. Instead we try and determine an EEP, which is close to the WWW server. A proxylet is then sent to the EEP, which downloads the page from the WWW server and compresses it and sends it to the webcache proxylet. The webcache proxylet then decompresses the page and returns it to the WWW browser. In our experiments we were able to compress the data for the transcontinental parts of a connection.
Another transform that we were able to perform was if we mime content type marked a URL as being an audio sample then a audio transcoder proxylet was downloaded close to the WWW server which held the sample and the audio was streamed back to the client. At the client end the browser was directed to a page which contained an applet which was capable of playing out the audio. So again in this case we were able to impose ourselves in the middle of a conversation. Which we were able to enhance without any change to the software at the end systems.
A limitation of our initial experiments was that the locations of the various EEPs were known a priori by the webcache proxylet. Another problem was that it is not always clear that it is useful to perform any level of transcoding. For example if a WWW server is on the same network as the browser it may make no sense to attempt to compress transactions.
From this application of proxylets two clear requirements emerged which would need to be satisfied from our application layer routing infrastructure.
The first requirement is to return information regarding proximity. A question asked of the routing infrastructure might be of the form: Return the location of an EEP, which is close to a given IP address. Another requirement could be the available bandwidth between EEPs. As well as perhaps the bandwidth between an EEP and a given IP address. An implied requirement also emerges. It should not take more network resources or time to perform ALR than to simply naively perform the transaction.
Given this location and bandwidth information the webcache proxylet can now decide if there is any benefit will be derived by transcoding or compressing a transaction. From this example a number of requirements emerge for facilities that need to be provided by the routing infrastructure. Not only is there a requirement for proximity information, there is also a requirement for bandwidth estimation. So a question asked of the application routing infrastructure may be of the form, find a EEP ``close'' to this network and also return the available bandwidth between that EEP and here.
A number of other experiments have been performed that provide different services to applications. A few of these are described below.
The Audio Transcoder Proxylet: This proxylet has been used in conjunction with the webcache proxylet to provide a transparent WWW audio streaming service. The audio transcoder uses HTTP/TCP to download audio samples from WWW servers and then converts the incoming audio stream to a RTP stream that is transmits to the users machine. The webcache proxylet is used to send a URL redirect to the user's browser in order to load a WWW page that contains a suitable audio tool configured as an applet. This mechanism makes it possible to deploy an audio player applet without special configuration of the WWW browser.
The Compressor/Decompressor Proxylets: These proxylets are used to perform special processing to files in order to enhance the performance of HTTP connections. The webcache proxylet is used to load a decompression proxylet on a local EEP machine, and a compression proxylet on the remote machine. The compression and decompression of the files can then be performed transparent to the WWW browser and server.
The Multicast Reflector Proxylet: This proxylet was developed to provide a Mbone connection to hosts in Australia. At the time the proxylet was written, Australia wasn't connected to the global Mbone. The reflector proxylet provides a mechanism for isolated networks to join multicast sessions. To demonstrate this, a reflector proxylet was executed at a machine at the Information Sciences Institute (ISI) located at the Massachusetts Institute of Technology (MIT). This reflector listens on a session description channel and forwards packets unicast to an EEP machine at the University of Technology, Sydney (UTS) running a peer reflector proxylet that multicasts the packets locally. It was thus possible to tunnel session information from ISI to UTS, via the reflector proxylet.
The Tcpbridge Proxylet: The Tcpbridge proxylet was developed to provide dedicated TCP connections to segments of the network that experienced poor latency. An observation was made that the direct network path from Southern France to UTS in Australia can be very poor. Far better response times could be gained b y first logging into a machine at University College London (UCL) and then logging into UTS. The proxylet was used to improve the latency observed for such a connection. The workings of the proxylet are fairly simple and straightforward. The proxylet accepts connections on a certain port and then in turn makes a connection to another host and port, with the data for both directions being relayed via the bridge (cf. snoop solution to wireless tails).
5.2. TCP bridge
One of our simplest proxylets, which was one of the first that we built, was a simple TCP bridging proxylet. The proxylet is really simple. One way of looking at this proxylet is that it allows application layer routing (ALR) of TCP streams. It could obviously also be extended to route specific UDP streams. The TCP proxylet runs on an EEP and accepts connections on a port that is specified when the proxylet is started. As soon as a connection is accepted a connection is made to another host and port.
An example of usage might be that you are in the South of France and want to make a TCP connection using telnet to Australia. However the international links out of Europe from France are very poor. You know that the connectivity from the UK to Australia is good. So you would like to route your TCP packets through the UK. A number of avenues are open. It may be possible to use the IP source routing options. However nowadays with so many possible attacks on networks source routed packets are highly likely to get dropped. Another option that we have used is to start a tcpbridge proxylet in the UK. Then make a TCP connection to the UK, which is relayed to Australia. A drawback to the current version of this solution required knowledge from the user about a possible better routing for packets.
A requirement that emerges from this scenario is we need the application routing infrastructure to return a number of EEPs on a particular path. We may ask of the ALR give me a path between node A and node B on the network, which minimises delay. We may also ask for a path between node A and B, which maximises throughput. Given a list of EEPs which constitute a path we can possibly run a tcpbridge on all he EEPs in the path to relay a connection. It may also be possible hat we require more than one path between node A and node B for perhaps fault tolerance.
5.3. VOIP gateway
Another proxylet that we have not written but intend to write is a proxylet, which is co-located with a gateway from the Internet to PSTN. The model is that a user is using their PDA, the PDA is equipped with a wireless network interface such as IEEE 802.11 or perhaps Bluetooth [blue]
The user would now like to connect to an IP to telephony gateway. The simple thing to do would be to discover a local gateway. More interesting might be to find the closest gateway to the telephony endpoint. An argument for doing this might be that it is cheaper to perform the long haul part of the connection over the Internet rather than by using the PSTN.
This seems to add perhaps another requirement. The ability to disseminate information about available services. The normal model for service discovery is to find a service in the local domain. We may have a requirement for service discovery across the whole domain in which EEPs are running. So a proxylet on an EEP which is providing a VOIP gateway may want to inject an opaque structure into the routing infrastructure which can be used by VOIP aware applications.
6. Activities During the Coming Year
During the last year, we have put into place the Active Services infrastructure of Section 2, and prepared most of the Proxylets of Sections 3 – 5. During the coming year, these components must be brought together, and others added. These components will come from the existing projects supported by DARPA (SCAMPI) [kirs1] and the European Commission (ANDROID) [kirs2]We expect to do the following:
1. Complete the Reliable Multicast Proxylets, integrated into FunnelWeb.
2. Complete the Audio Transcoding Proxylet, based on the RAT Transcoder
3. Complete the Filtering Gateway as a Proxylet, based on the MECANO UTG
4. Develop the Recording Cache Proxlyet from the SCAMPI work
5. Develop the Playback Proxylet from the SCAMPI work
6. Verify that we can set up a Wide Area Active Node network, with the Nodes’ host configured by the Xbone, ISI’s VPN engine.
7. Start Deploying some of these Proxylets with FunnelWeb over a non-trivial network – probably including the Xbone and possibly the Abone.
8. Liaise with SCAMPI to ensure that we have an appropriate security infrastructure.
7. The November PI Meeting
7.1. Collaborative Working Requirements
DARPA is very keen that the different projects funded under their Active Networks programme collaborate together. On the whole, the ALAN approach is different from others in the programme. After considerable discussion, it seemed that the right partners for the RadioActive project would be:
Garry Minden (Kansas U, Kansas U, Kansas; gminden@iitc.ukans.edu) and Joe Touch (ISI, Santa Monica, California; touch@isi.edu). We hoped to integrate our activities also with the Mobile routing work of Garcia-Lunar at UC Santa Cruz.
In practice, we have been unable
to arrange any meaningful collaboration with Kansas U, and are going to limit the
Atlanta demonstration to work with ISI. We hope that a broader collaboration
will be achievable for the following demonstrations.
7.2. The Non-UCLActivities
Kansas U has three relevant activities in three areas:
- Putting together a rugged 12-machine package running Linux. It can be reconfigured dynamically.
- Making an easily packaged active node (Node OS, Planet etc)
- Putting in composable protocols
It is not obvious that the second and third meld in with a demonstration of UCL work. The first could be very useful provided we consider it as a useful platform, with which several of the joint demonstration could be done. Nevertheless, it looks comparatively straightforward to make an integrated demo, and we would learn a lot from it. I will assume that it happens.
ISI in the X-Bone activity has a way of setting up a set of Hosts as a virtual network – with the set up and running as a secured VPN. This will fit in very well with wide-area demonstrations of the FunnelWeb system.
7.3.
UCL Activities
UCL will mount some of the Proxylets described in Sections 4-6 on EEPs as Active Services. Those relevant to the demonstration will be chosen from the following:
- Self organising components
Reliable multicast
· Media stream filtering based on UTG
·
Transcoding of audio based on
RAT
In the next year, we expect to capitalise on the integration of the components described above. We have described here the Proxylets already developed; in addition some of the other components mentioned above will be made part of the FunnelWeb Proxylets.
For
demonstration at the end of this calendar year, we will use mainly the
Proxylets currently operational. This should include a set of audio
transcoders, already implemented, and an algorithm for organising them - the
data from the SOAR infrastructure can feed into this system and we expect to be
able to demonstrate this towards the end of year 2000. This will give three
self-configuring approaches to improving network performance, from
multicasting, caching and transcoding; each of these addresses a different
problem in coping with qualitative and quantitative heterogeneity in the
Internet today and tomorrow. Not all of these will be shown in the November
demonstration, however.
7.4. A
schematic of the Atlanta Demo
The Atlanta PI demonstration will need to be worked out carefully at least between Kansas U, UCL and ISI. However, this report makes a stab at a configuration. The demonstrations will run audio and NTE on the collection of Hosts, gateways and networks. These are indicated in Fig. 4 below:
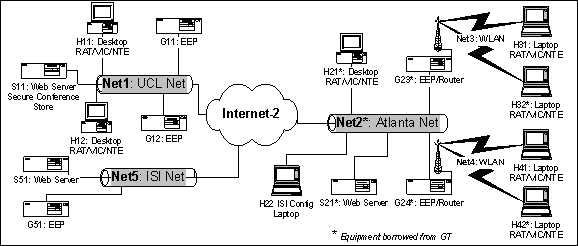
Figure 4 Schematic of the DARPA PI Atlanta
Configuration
The demonstration will include a number of networks (Nxx), Gateways (Gxx), Hosts (Hxx) and Web Servers (Sxx). The Networks will include Internet-2 connecting UCL (Net1), [Kansas], ISI (Net5) and Georgia Tech (Net2, 3 and 4). Net2 will be a wired Ethernet, connected to two separate WAVELAN networks (Nets 3 and 4). G1x, G2x run the audio transcoding and reliable multicast proxylets. H21 will be a fixed host, and H31 and H41 will wander. The VPN will consist of all the hosts, routers and gateways in use as demonstration machines at UCL, ISI and the demo site. The VPN from ISI will include the fixed end points; for this reason it can include all the components in Net 1, and the end-user devices (and gateways) on Nets 3 and 4. Thus the Servers, Hosts, Edge Nodes and Application Gateways will all be considered. The whole configuration will need further discussion. There will be Web Servers S11, S51 and S21 at UCL, ISI Georgia Tech to allow down-loading of Proxylets. It would seem that the whole configuration could be set up as a VPN by ISI, with the Proxylets and applications configured from UCL or Atlanta.
8. Staffing and Acknowledgements
8.1. Staffing
While the funding from DARPA under the RADIOACTIVE Project has funded some of these activities, it has not been a very high proportion. This is partly because the project is only funded for one research student and one research Fellow, and partly because it took some time to get even these staff completely on board.
The UCL staff associated with the RADIOACTIVE project has been:
· Jon Crowcroft - Co-PI
· Peter Kirstein - Co-PI
· Herman de Meer - long term research
· Piers O'Hanlon - maintaining Linux systems
· Kris Hasler - deploying Windows version of EEP/EEP
· Ibraheem Umaru-Mohammed - implemented RLC and NTP part of SOAR.
We acknowledge also the work of Lorenzo Vicisano and Luigi Rizzo for developing the RLC and RMDP protocols. We also thank Prof. Michael Fry and Atanu Ghosh for their work on FunnelWeb and the whole EEPS software. During 1999/2000 the work has been co-funded by British Telecom under the ALPINE project, and we expect this to continue during 2000/2001.
Almost exactly at the end of this first year, the European Union funded project, ANDROID, started; this will provide end system applications, and will apply the ideas to mobility amongst other things. We expect to work further with Joe Touch at ISI in deploying EEPs over the X-bone technology. To this end, we are already running an EEP on our CAIRN infrastructure at UCL.
8.2. Travel
During the last year, funds from RADIOACTIVE have helped defray expenses for attendance at IETF, IRTF Reliable Multicast and End2end and BUDS groups, It has also helped finance attendance at SIGCOMM and DARPA PI Meetings.
References
[alan] ``The ALAN Programming Manual'', http://dmir.socs.uts.edu.au/projects/alan/prog.html.
[amir] E Amir et al: "An Active Service Framework and its Application to Real-time Multimedia Transcoding," ACM Computer Communication Review, vol. 28, no. 4, pp. 178--189, Sep. 1998
[banc] A Banchs et al:``Multicasting Multimedia Streams with Active Networks'', International Computer Science Institute, Technical Report, `97
[blue] [http://www.bluetooth.org/]
[cald] M Calderon et al: "Active Network Support for Multicast Applications," IEEE Network, vol. 12, no. 3, pp. 46--52, May 1998.
[crow1] J.Crowcroft et al: ``Internetworking Multimedia'', UCL Press.
[crow2] Mechanisms for Supporting and Utilising Multicast
Multimedia, Proposal to DARPA for an extension to D079, Principal Investigators
Jon A. Crowcroft and Peter T. Kirstein, Department of Computer Science,
University College London, 17 June 1999
[duff] N Duffield et al: “Multicast Inference of Packet Delay Variance at Interior Network Links”
[fenn] W.Fenner: “Internet Group Management Protocol, Version 2'', Internet Draft, January `97.
[ffn]: [http://www.ffnet.com/press/062800_award.html].
[fran1] P Francis PhD thesis, UCL 1992. ftp://cs.ucl.ac.uk/darpa/pfrancis-thesis.ps.gz
[fran2] P Francis: “YALLCAST arhictecture”, http://www.aciri.org/yoid/docs/index.html
[fry1] M.Fry et al: “Application Level Active Networking'', Fourth International Workshop on High Performance Protocol Architectures (HIPPARCH '98), June 98
[fry2] M Fry et al, “Application Level Active Networks”, in Computer Networks and ISDN Systems, http://dmir.socs.uts.edu.au/projects/alan/papers/cnis.ps
[fry3] M Fry et al,: “The FunnelWeb System”, submitted to infocom99
[hand] M.Handley et al: “Internet Multicast Today'', The Internet Protocol Journal
[hang] [http://www.cs.cmu.edu/~hzhang/multicast/rm-trees/
[hart] J Hartman et al: "Joust: A Platform for Communications-Oriented Liquid Software", IEEE Computer 32, 4, April 1999, 50-56.
[kirs1] http://www.cs.ucl.ac.uk/research/scampi/
[kirs2] http://www.cs.ucl.ac.uk/research/android/
[kouv] I Kouvelas et al: “Self Organising Transcoders (sot)”, NOSSDAV 1998, ftp://cs.ucl.ac.uk/darpa/sot.ps.gz
[kum] V.Kumar: “MBone: Interactive Multimedia On The Internet.'', Macmillan Publishing 1995.
[math] M Mathis et al: “The macroscopic behaviour of the TCP congestion avoidance algorithm.'' ACM Computer Communication Review, 27(3), July 1997.
[mccann] S.McCanne et al “Receiver-driven Layered Multicast'', SIGCOMM `96, August 96.
[minc] Multicast Inference of Network Congestion (minc) http://gaia.cs.umass.edu/minc
[mont] A Montz et al: "Scout: A Communications-Oriented Operating System," Department of Computer Science, The University of Arizona, no. 94-20, 1994.
[nimrod] “New Internet Routing: (a.k.a nimrod) http://ana-3.lcs.mit.edu/~jnc/nimrod/docs.html
[ozd] V Ozdemir et al: “Scalable, Low-Overhead Network Delay Estimation”
[padh] J Padhye et al: “Modeling TCP Throughput: A Simple Model and its Empirical Validation," ACM Computer Communication Review, vol. 28, no. 4, pp. 303--314, Sep. 1998.
[real] [http://www.real.com/]
[reja] R Rejaie et al: ”An End-to-end Rate-based Congestion Control Mechanism for Realtime Streams in the Internet”, Proc. Infocom 99 http://www.aciri.org/mjh/rap.ps.gz
[rek] Y Rekhter et al: “An Architecture for IP Address Allocation with CIDR”, RFC 1518 , 1998
[riz1] L Rizzo et al: “A Reliable Multicast data Distribution Protocol based on software FEC techniques'', The Fourth IEEE Workshop on the Architecture and Implementation of High Performance Communications Systems (HPCS '97), June `97
[riz2] L.Rizzo et al: “RMDP: an FEC-based Reliable Multicast protocol for wireless environments'', Mobile Computing and Comunications Review, Volume 2, Number 2
[rlc] “Receiver Driven Layered Congestion Control (rlc)” ftp://cs.ucl.ac.uk/darpa/infocom98.ps.gz and ftp://cs.ucl.ac.uk//darpa/rlc-dps.ps.gz
[rtpq] RTP Quality Matrix http://www-mice.cs.ucl.ac.uk/multimedia/software/rqm/
[scott] D Scott Alexander et al: "The SwitchWare Active Network Architecture," IEEE Network, vol. 12, no. 3, pp. 27--36, May 1998.
[stem] M Stemm et al: “A Network Measurement Architecture for Adaptive Applications”, Proceedings of IEEE Infocom 2000.
[tberl] T.Berners-Lee: “The World-Wide Web initiative''. In Proc. Int. Netw. Conf. (INET), August `93
[tenn1] D Tennenhouse et al: “A Survey of Active Network Research'', IEEE Communications Magazine, January `97.
[tenn2] DL Tennenhouse et al: “Towards an Active Network Architecture'', ACM Computer Communication Review, vol. 26, no. 2, pp. 5-18, Apr. 1996.
[thei] W Theilmann et al: “Dynamic Distance Maps of the Internet”, Proc. IEEE Infocom 2000.
[vic] L.Vicisano: “Receiver-driven Layered Congestion control'', http://www.cs.ucl.ac.uk/external/L.Vicisano/rlc.
[vill] C Villamizar: Work in progress, i-d - ftp from http://www.ietf.org/ietf draft-ietf-ospf-omp-02.txt
[weth] D Wwetherall et al,: "Introducing New Internet Services: Why and How," IEEE Network, vol. 12, no. 3, pp. 12--19, May 1998.
[yead] N Yeadon: “Quality of Service Filters for Multimedia Communications”, Ph.D. Thesis, Computing Department, Lancaster University, Bailrigg, Lancaster, LA1 4YR, U.K., May 1996. Internal report number MPG-96-35.