Abstract
This is a 6–monthly report for the second year of the DARPA-funded Radioactive Project, funded from July 1 1999.
We had previously implemented and demonstrated an Application Layer Active Network (ALAN) infrastructure, known as FunnelWeb. This infrastructure permits the dynamic deployment of active services in the network, but at the application level rather than the router level. With this technology, the advantages of active networking are realised, without the disadvantages of router level- implementation.
Our first year work was demonstrated at the DARPA PI meeting at Atlanta, integrated with the XBone work of Joe Touch at ISI; the demonstration is described in this report. We have both investigated a number of approaches to providing QoS, and made several relevant contributions to the IETF. Our recent applications work in Active Networks has concentrated on Virtual Private Networks; here we have laid the foundation for the incorporation of policies in the near future. Finally, we describe our progress in moving all our systems over to IPv6.
1. Introduction and Background
1.2. Stated Aims of RADIOACTIVE and our Progress
1.3. Organisation of the Report
2. The Radioactive/XBone Demonstration
2.2. The RADIOACTIVE Infrastructure and
FunnelWeb
3.1. Congestion Control Algorithms and
Weighted Fairness
3.2. Fault Tolerance for Traffic
Aggregate treatment of DiffServ
3.3. Integrating IP Traffic Flow
Measurement
3.4. Lower than Best Effort: a Design and
Implementation
4.3. Traffic Flow Measurement API
5. Recent Work on Virtual Private Networks and Other Active Services
1. Introduction and Background
1.1. Introduction
Active Networks are a novel approach to
networking that aims to permit user-defined computation within the network.
This architecture provides applications with a mechanism to load
protocol-processing code into the network on demand. Traditional networks
suffer from problems of slow service evolution due to the inflexibility of the
existing infrastructure. Active Networks address the problems of integrating
new services and technologies; they strive to overcome the problems of poor
performance levels and to extend the functionality of the network
infrastructure. The background of the present RADIOACTIVE project has been
discussed in the first annual report [Crow1], and will not be repeated.
If the user is empowered with ability to inject
custom programs into the network, then security is of major concern. The Active
Network architecture must provide a framework that allows services to be
expressed safely, easily and with minimum impact on other network users. The
architecture must be flexible enough to accommodate new services, and
restrictive enough to meet security and performance goals. We believe that the
ability to tune the network service to a particular application is a
justifiably important issue, if the security properties of network are
protected. The approach to Active Networks adopted in the RADIOACTIVE project
is at the Application Level. This is the programmable switch technique, in which
customised programs are placed into service nodes, which can be loaded and
executed on demand. The service nodes provide an execution environment for
running the customised programs, and also have the capability to perform
computations on the traffic passing through the node. The user therefore has
the flexibility to send their data through specific service nodes for code
processing. The software base, which is at the heart of the RADIOACTIVE system,
is called FunnelWeb [Ghosh], and was described in some detail in the
first annual report [Crow1].
There are a number of existing applications that
apply the concepts of active services in traditional networks. This class of
services includes firewalls (monitor and filter the traffic that comes in or
out of a network), web proxies (used to provide a user-transparent service
tailored to the serving and caching of web pages), video gateways, and nomadic
routers to name a few.
1.2. Stated Aims of RADIOACTIVE and our Progress
In our proposal, we proposed to investigate the
following:
·
Policy Derivation
·
Application Level
Routing
·
Packet Forwarding
with DiffServ
·
Location of key
Modules
·
Algorithms for Forwarding
·
Security Architectures
·
PKIs
·
IPSEC/IKE
·
Depositories
·
Secure Conferencing
·
Security in Relays
·
QoS and Security
Policy Modules
·
Demonstration Applications
·
Measurement and Monitoring
·
Large-scale Control of Audio Devices
During the first 12 months, we expected to address problems in the
following areas:
Work Package 1
·
Application Level
Routing, with multimetric criteria
·
Inter-domain
proxylet Services (including Receiver-driven Layered Congestion Control (RLC)
algorithms
·
Dynamic Reservation
Protocols
·
Object Location
Services
·
Security Services
·
Inter Domain
Proxylet Services
We expected to write a report within the first 18 months on the
architecture
Work Package 2
Here we expected to provide a measurement
framework, but only after 24 months
Work Package 3
Here we expected during the first 12 months to develop relays for stream
aggregation, filtering and coding, and proxies that dealt with reliable
multicast establishment.
In practice, we have
pursued our activities correlate closely with our intentions with one
exception. In the original proposal we were not sure whether another proposal
[Crow2] on security technology would be funded. In the event that second
proposal was funded also, and the security activities were pursued in that
project [Crow3]. More recently, we have used VPNs as a key example of Active
Network technology; hence the work of the two projects has been closely
integrated. Much of the first year was spent in integrating the ALAN
infrastructure with our media components, and then with the XBone of Joe Touch;
this was demonstrated at the PI meeting in Georgia Tech in December.
1.3. Organisation of the Report
This report is organised as follows. We first describe, in Section 2, the
demonstration we carried out at the PI meeting in Atlanta. This will be
extended throughout the rest of the project.
We will be applying our active infrastructure to
a number of situations where Quality of Service (QoS) can be provided. In
Section 3 we describe a number of activities which have addressed algorithms
for providing QoS, and for which we have made detailed presentations. Many of
these will be implemented in the Active network environment in the last year of
the project. Various contributions have been made to the IETF, partly arising
from the work in Section 3; these contributions are described in Section 4.
The implementation work in
the Active Services has concentrated on the VPN applications over the last few
months. This work is described in Section 5. Finally it is our intention to
move the implementations over to IPv6; our progress here is described in
Section 6.
2. The Radioactive/XBone Demonstration
2.1. Introduction
This Section presents an overview of the RADIOACTIVE demonstration held at the Atlanta PI meeting in December. The primary purpose of this effort was to show a snapshot of the state of the building blocks produced by UCL for RADIOACTIVE, and their communications with the XBone system from ISI. Specifically, UCL will demonstrate its activities in the integration of these building blocks, its progress to that date, and our observations of what needs to be done to help facilitate the continued collaborative integration process.
There were three distinct demonstrations. The objective of these exercises was to show the capabilities of software modules/platforms produced, their integration, and a determination of what further needed to be done to continue the integration and collaboration process.
2.2. The RADIOACTIVE Infrastructure and FunnelWeb
We have previously proposed, implemented and demonstrated an approach to active networks based on Application Layer Active Networking (FunnelWeb) [Fry]. We believe that this approach can achieve many of the benefits ascribed to active networks without the considerable drawbacks evident in the implementation of active networks in IP routers. There was a complete discussion of the FunnelWeb system in [Crow1]; we provide here only enough information to make the remainder of this section comprehensible.
Our approach has been validated by developments in the commercial Internet environment. Some Internet Service Providers (ISPs) will support servers at their sites supplied by third parties, to run code of their (3rd parties') choice. Examples include repair heads [Hang] with servers in the network, which help with reliable multicast in a number of ways. In the reliable multicast scenario an entity in the network can perform ACK aggregation and retransmission. Another example is Fast Forward Networks Broadcast Overlay Architecture [Ffh]. In this scenario there are media bridges in the network. These are used in combination with RealAudio [Real] or other multimedia streams to provide an application layer multicast overlay network.
At this time it is the case that “boxes” are being placed in the network to aid particular applications. The two applications that we have cited are reliable multicast and streaming multimedia delivery. There are other such boxes being placed inside ISP’s networks, to help with content delivery.
We believe that rather than placing “boxes” in the network to perform specific tasks, we should place generic boxes in the network that enable the dynamic execution of application level services. We have proposed an ALAN environment based on an Execution Environment for Proxylets (EEP). In our latest release of this system we rename the application layer active nodes of the network Execution Environments for Proxylets (EEPs). By injecting active elements known as proxylets on EEPs we have been able to enhance the performance of network applications.
In our initial work we have statically configured EEPs. This has not addressed the issue of appropriate location of application layer services. This is essentially an Application Layer Routing (ALR) problem.
For large-scale deployment of EEPs it will be necessary to have EEPs dynamically join a mesh of EEPs, with little to no configuration. As well as EEPs dynamically discovering each other applications that want to discover and use EEPs should also be able to choose appropriate EEPs as a function of one or more form of routing metric. Thus the ALR problem resolves to an issue of overlaid, multi-metric routing.
Our infrastructure is quite simple and is composed of two components. Firstly we have a proxylet. A proxylet is analogous to an applet or a servlet. An applet runs in a WWW browser and a servlet runs on a WWW server. In our model a proxylet is a piece of code, which runs in the network. The second component of our system is an (Execution Environment for Proxylets) EEP. The code for a proxylet resides on a WWW server. In order to run a proxylet a reference is passed to an EEP in the form of a URL and the EEP downloads the code and runs it. The process is slightly more involved but this is sufficient detail for the current explanation.
In our initial prototype system ``FunnelWeb'', the EEP and the proxylets are written in Java. Writing in Java has given us both code portability as well as the security of the sandbox model. The FunnelWeb package has been run on Linux, FreeBSD, Solaris and NT.
2.3. XBone & EEPs
The first demonstration involved the operation of the FunnelWeb Execution Environment for Proxylets (EEP) over an XBone overlay.
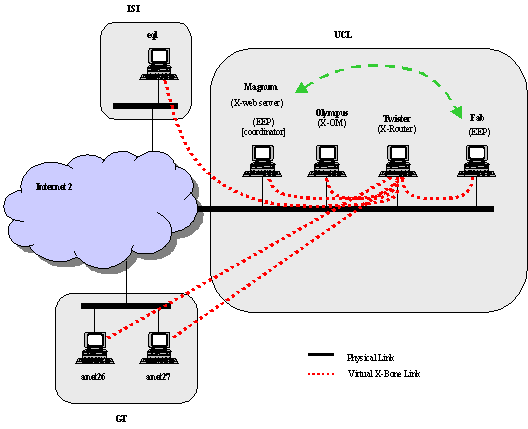
Figure 1 Schematic of System showing EEP
Registration in an XBone System
Specifically, we showed the ability of EEPs, through the use of the Routing & Discovery proxylets, registering themselves with a single Co-ordinator EEP[1]. The registration process is an automated feature operating independently from any user-application type of proxylet. The XBone software platform, developed and distributed by ISI, operate over several nodes within UCL’s IP network, SAIC, ISI and the Georgia Tech’s meeting site at Atlanta.
Figure 1 presents a topological view of the actual hosts and routers, as well as the XBone virtual overlay. In this figure, the XBone overlay is depicted as dotted red lines. Its virtual topology is that of a star structure. The node titled Twister acts as the single XBone router, with the other nodes (q1, anet26, anet27, Magnum, Olympus, Twister and Fab) acting as XBone hosts. Magnum is also designated as a web server (running Apache), and an EEP co-ordinator. Finally, for this demonstration, Olympus acts as the XBone overlay manager.
This demonstration only focuses on the ability of EEPs to communicate over the XBone for the purpose of EEP registration.
2.4. XBone & UTG Proxylet
This demonstration showed the operation of the UCL Translating Gateway (UTG). This is a proxylet that provides a multicast-to-unicast gateway so that users with only unicast connectivity were able to join and participate in multicast sessions. In this exercise, we showed the UTG proxylets operating over an XBone overlay.
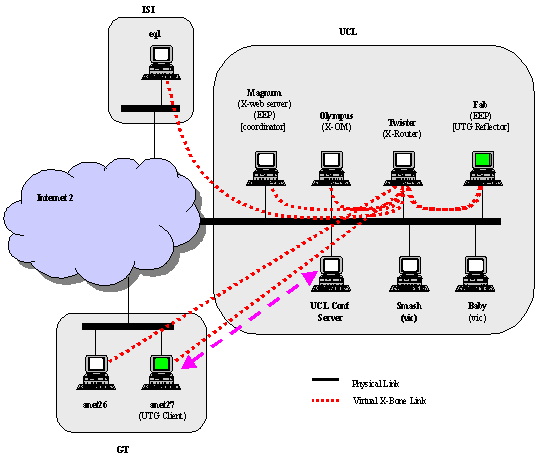
Figure 2 shows the same physical and logical connectivity as Figure 1. Additions are made to the earlier figure in
the form of a UTG Client proxylet loaded onto Anet27, and a UTG Reflector
(i.e., server). These two nodes participate in the multicast-to-unicast
gateway communication. In addition two other machines (Baby and Smash) originated video via VIC.
Figure 2 Schematic showing a UTG Reflector Proxylet allowing remote
Unicast conference clients to participate in multicast conferences via XBone.
2.5. Web-Cache Proxylet
This demonstration showed the operation of Web Cache Proxylet developed by the University of Technology, Sydney (UTS). From a general perspective, this proxylet was used to improve the performance of existing web cache architectures – in which a proxy is used to store and locally redistribute web pages that have been retrieved previously and recently by other users. The improvement offered by this proxylet is that it provides compression/decompression of files (specifically, text files).
The operation of the proxylet is divided into three components: (1) interaction with a local proxy cache, (2) discovery or remote EEPs located near destination web locations, (3) distribution and activation of compression (formally titled htmlzipper) proxylets. Figure 3 below shows a general characterisation of the demonstration. As one can see in the figure, anet28 is the host that contains the web browser exercised by the user. The browser is configured to send its requests to scary, which is the EEP that contains the web-cache proxylet. Upon receiving the request for a text file, it first queries the local cache to determine if it has a local copy. Upon failure, the proxylet then determines that an EEP (located at Degas.time.saic.com) exists near the destination web site (Prima.time.saic.com). scary then sends the htmlzipper proxylet to the remote EEP, and informs it to locally download the file, compress it, and send it to scary. scary then decompresses the file and sends it to the browser on anet28.
An important distinction to note is that unlike the first two
demonstrations, this third effort did not include the use of the XBone
overlay. This is because the version of
the XBone software platform available at the time supported only a rudimentary
set of topology overlays (Star, Linear, and Ring). However, the discovery and routing proxylets used by the
web-cache proxylet used a type of proximity criteria to determine if the
destination web location has a nearby EEP.
Given the lack of a more robust topology generator by the XBone
software, the web-cache proxylet could not operate in an effective manner. Since the time of this demonstration, ISI
has developed a mesh topology that will help facilitate the integration of the
web-cache proxylet within the XBone.
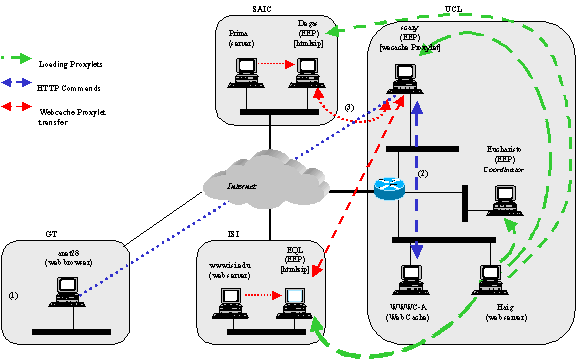
Figure 3 Schematic of System
showing Web Cache and Web Server between UCL, ISI, SAIC and GT.
3. QoS Activities
We have done considerable work on mechanisms for Quality of Service. It is intended to put many of these into proxylets during the remainder of the project. A number of publications have come out of this work. These include the following:
Gevros, P, Crowcroft, J, Kirstein, PT and S. Bhatti: ”Congestion Control Mechanisms and the Best Efforts Service Model”, To Appear in IEEE Networks, 2001
De Meer, H and P. O'Hanlon: “ Segmented Adaptation of Traffic Aggregates”, To Appear in IWQoS 2001
Carlberg, K. Gevros, P., and J. Crowcroft: “Lower than Best Effort: a Design and Implementation”,
Each of these suggests algorithms that could be implemented in the FunnelWeb system [Fry].
3.1. Congestion Control Algorithms and Weighted Fairness
Gevros has started writing up his thesis, which has a major portion concerned with “Distributed Linear Controls and Weighted Fairness”. This work is related to the work of Chiu and Jain [Chiu], who proved that among all linear control strategies the Additive Increase and Multiplicative Decrease (AIMD). Linear Increase, Exponential Decrease is probably a more appropriate name, however the AIMD term stuck. That strategy leads the system to a fair and efficient operating point regardless of the initial state, the resource capacity and the number of users in the system.
AIMD has been used in the TCP window adjustment algorithm and has served the Internet remarkably well for many years. However, the assumptions upon which the optimality of the AIMD strategy was based are now challenged by the Internet's growth and the new application and economic requirements. In this work he considers that the need for distribution is still a valid requirement but challenges the assumptions that a single congestion control algorithm be deployed universally, and that non-discriminative fairness implies equal rights to resource allocation.
In our model the users of the network are not humans but ``software agents'' (e.g. applications or transport protocols) which have associated with them a certain control behaviour that depends on the feedback received from the network. The agents acquire resources (bandwidth) and when the rules of interaction are appropriately defined the collective actions of all the agents constitute what is called ``distributed intelligence'' which can achieve resource allocation outcomes more efficient and scalable than those achieved by the best possible centralised controller. Moreover, in a distributed environment like the Internet, centralised control is not possible because resources are owned/managed by different administrative authorities. Therefore the decision making process is distributed and the goal is to discover the ``appropriate rules of interaction'' for efficient and fair utilisation of the resource.
The work is motivated mainly by the following considerations:
· A single universally deployed congestion control algorithm seems rather unrealistic.
Real-time and streaming multimedia applications cannot tolerate drastic rate reductions by a multiplicative decrease factor of 0.5 as in TCP congestion control.
· New congestion control algorithms routinely invoke AIMD principles as these strive to `` interact fairly'' with TCP.
However their use of less drastic rate decrease measures upon congestion combined with less aggressive increase, generally is not sufficient.
· Fairness should not necessarily imply non-discrimination and equal rights to resource allocation.
In an environment of differential pricing it is expected that more resources be allocated to users who are willing to pay higher prices compared to others. It is reasonable that the relative allocation of resources be directly proportional to the ratio of their users’ rights for allocation, which introduces the notion of Weighted Fairness.
· Relative service differentiation is a powerful concept, which avoids the scalability and complexity problems associated with the implementation of guaranteed service, but can still offer differentiated QoS within the best-effort context of the current Internet service.
· The economic policy of bandwidth sharing has been built into the transport protocols almost as a side effect of congestion control and thus transport-level differentiation follows as the natural extension.
In particular in a network with application layer active components (e.g. web caches) or popular server sites (``hot spots'') from where a large number of flows originate. Transport level differentiation enables the end-user to optimise specific objectives (price, performance) and has the major advantage of being a decentralised resource allocation method that suits the nature of the Internet well.
The end-to-end argument is a set of design principles first outlined in the early eighties, which guided Internet design. The argument states that application level functions should not be implemented inside the network because ``the function in question can completely and correctly be implemented only with the knowledge and help of the application standing at the endpoints of the communication system''.
· Resource acquisition in our case is a high level function that involves application and/or human user intervention.
· Linear control algorithms are robust and simple to implement.
Non-linear or even equation-based controls tend to be complicated and more sensitive to system parameters.
· Although treatment of the network as a single resource appears overly simplistic, it can provide several useful insights on the dynamic behaviour of congestion control algorithms and an intuitive model from an end-user's point of view for the introduction of pricing mechanisms.
Users can understand that different transactions may be priced differently; the price of the resource may change because the underlying components involved in the transaction may have changed but they do not particularly care about which components are actually involved e.g. expensive links, more links etc.
· The single bottleneck link scenario.
The discussion about the congestion control and performance properties of TCP has dominated network research in the last decade. The networking literature is full of examples of ``dumbbell'' topologies where a set of hosts sends to another set of receiving hosts through a single bottleneck link.
Studies on the effect of diverse congestion control behaviours tend to ignore the effects due to the actual populations using a particular type of control.
In his study [Gevros], Gevros has looked in detail at different mechanisms for adjusting the AIMD parameters. He studied a system with classes of AIMD controls with parameters, populations and weights, so that all users of class (and) have weight corresponding to their relative right to resource share. He showed that such a system converges to the optimal state of efficiency and fairness. Most of the congestion control mechanisms presented in his paper, the router-based ones in particular, were almost exclusively studied in the context of guaranteed QoS and real time traffic. He considered that there is a widely spread misconception that best-effort service model necessarily implies simple FIFO queues in the routers. If used appropriately the WFQ mechanisms could provide, for instance, preferentially lower delays to ``fragile'' interactive applications (like telnet) without striving to provide any quantitative QoS guarantees. His main reason for pursuing QoS was the concerns about the requirements of emerging real-time and streaming multimedia applications, which could not be met in the existing service model. Nevertheless it has been amply demonstrated that many popular applications (packet audio, video-conferencing) are able to adapt to dynamic network conditions by changing their transmission rate using different coding techniques, and therefore perform sufficiently well under moderate congestion levels.
Thus it is likely for the Internet to evolve towards a best effort network which, if controlled and provisioned appropriately, will be able to satisfy the majority of popular applications that are willing to tolerate service deterioration due to transient congestion. This could sustain a large market for best-effort service and would limit the applicability of service models for guaranteed QoS to corporate Intranets and virtual private networks.
Even when the Internet is used for much of the traffic, with special Intranets at either end, the use of Active components at either end of the Internet portion (both ingress and egress) could allow appropriate mechanisms to be employed. These would give a better end-end service to the applications within a mean QoS service between the two ends.
3.2. Fault Tolerance for Traffic Aggregate treatment of DiffServ
Another activity on Congestion control in heterogeneous QualityofService (QoS) architectures, but even more targeted to Active Service implementation, has been started by de Meer and O’Hanlon [DeMeer]. Taking the current trend towards Differentiated Services (Diffserv) as a likely candidate for future Internet QoSarchitectures into account, their solution is based on three constituent parts:
· Aggregated congestion control,
· Domainbased congestion control,
· Classofservice based congestion control.
Generally, the overall framework for congestion control, as suggested here, reflects essential properties of underlying QoS architectures and their instantiations in real implementations. To achieve highly flexible architectures, we believe that Application Level Active Networking is very suitable to provide an enabling technology for a seamless and immediate integration of the proposed scheme into current architectures.
Issues in sharing bottlenecks and techniques of how to enforce fairness among competing elastic and nonelastic applications has triggered a hefty discussion within the Internet research community recently. While some form of fairness among competing flows appears appealing to one camp of researchers others are worried about the implied overhead of policing and enforcing control policies on a flow basis. To yet another camp, the idea of enforcing fairness in sharing bottlenecks does not appear as compelling at all. Disregarding implementation and runtime overhead, a fair sharing of bandwidth may not easily translate to a concept of fairness on the application level as QoS requirements and pricing conditions may vary vastly. While the concern about congestion control is being widely shared the jury is still out on measures of how to approach the problem [Floy2]. We consider one approach to this problem in this section, and have done some related studies in Section 3.1.
QoS architectures within the confines of the DiffServ model are currently being introduced into the Internet to provide preferred handling of privileged traffic load classes [RFC2475]. Subscribers to such a privileged class expect to receive a higher level of service at a premium price. Within the confines of DiffServ architecture, and in particular within Assured Forwarding (AF) subclasses, congestion may still arise and QoS violations may occur at times, despite traffic conditioning and resource provisioning. QoS architectures rely on classdedicated resource provisioning of some sort and thus try to reduce the probability of congestion occurrence on the one hand an the impact of congestion events on privileged traffic on the other hand. Since the possibility of such QoS fault is likely to be an occasional matteroffact characteristic of any DiffServ architecture, we take that systematically into account as part of an overall model of QoS semantics. Therefore we characterise QoS architectures not only in terms of assured transport privileges, but also in terms of adequate recovery measures in the presence of QoS faults as a result of congestion. Most current QoS architectures do not have sufficient built-in error resilience, or QoS fault tolerance. To remedy this, we propose the three elements of aggregated congestion control, domainbased congestion control, and classofservice based congestion control. The approach contributes to the solution of some of the pending congestion control problems, by introducing new control and management functions into existing architectures. Introducing new services into an existing networking environment, however, is a challenge of its own, as hardware vendors have traditionally solely controlled reprogramming of routers. While Active and Programmable Networking technologies have been pursued as a possible onceandforall solution to the often-lamented inflexibility of networking infrastructure by the research community, there is still a long way to go for Active Networking infrastructure to be widely available [Camp]. Our pragmatic solution, therefore, relies on our Application Level Active Networking (ALAN) infrastructure, called FunnelWeb that requires only a minimum support from the networking layer [Ghosh]. This approach avoids many performance and security risks that have often been considered as a main hindrance to a more general acceptance of Active Networks. In [DeMeer], we introduce the notion of QoS faulttolerance measures in DiffServ architectures and then look at segmented adaptation as a special case of it. The paper includes also a discussion of an implementation of the segmented adaptation scheme based FunnelWeb. This is followed by simulation studies and first numerical results.
The paper is based on the concept of segmented adaptation of traffic aggregates. This concept reflects essential characteristics of evolving DiffServ QoS architectures, which are being built on the principle of composing endtoend QoS services from autonomous segments that are characterised by their per domain behaviours (PDB). The entities of interest are traffic aggregates of given quality and quantity, which are negotiated between neighbouring providers who autonomously operate and control their domains. Segmented QoS fault tolerance mechanisms, of which adaptation of traffic aggregates is designed to be a particular case, are to be provided to enhance endtoend QoS and to confine or to reduce the probability of occurrences of endtoend QoS failures. We envision segmented QoS fault tolerance as being the necessary glue to form endtoend QoS services from welldefined PDBs as building blocks.
Our approach has been built on an extended concept of distributed bandwidth brokers that control the adaptation of traffic aggregates according to policies provided by Service Level Agreements (SLAs). An actively extended SLA specifies serviceclass dependent on how parameters and values of an SLS are reset upon reception of a congestion signal. As a result, the advertised bandwidth at an egress link of an upstream edge router is lowered. It is up to the upstream bandwidth broker to push the congestion control signal further upstream or to mask the QoS failure of the downstream segment by local management operations such as by using QoS routing mechanisms. Ultimately, a congestion control signal may reach one or more access domains so that some applications could face presssure to adapt accordingly. But congested core routers have no notion of application flows and, consequently, are not extra loaded by flowbased scheduling or flowbased signalling and related processing overhead or fairness concerns.
Building adaptation on edgetoedge segmentation and aggregation of traffic is believed to result in a highly scalable approach for congestion control, or QoS fault tolerance as the more general concept for that matter. Decoupling applications and network transport mechanisms further within the DiffServ model is likely to increase the overall flexibility in terms of the endtoend argument. The introduction of network selfprotection as an immediate consequence of the approach eliminates the reliance on the co-operation of applications in the face of congestion, while on the same time being fully backward compatible with TCPfriendly schemes for congestion control.
As a proof of concept, we are working on an implementation of a testbed, based on our FunnelWeb platform that allows the introduction of new services into an existing networking infrastructure. While we have obtained early simulation results on the effectiveness of segmented adaptation of traffic aggregates, many open problems remain. These are discussed in [DeMeer].
3.3. Integrating IP Traffic Flow Measurement
Traffic measurements are required by several applications in network and service management. They are important for the evaluation of the efficiency of the mechanisms proposed earlier in this section. For Internet measurements, the IETF has designed a Real-time Traffic Flow Measurement (RTFM) architecture [RFC2722] providing high functionality, but requiring rather complex configuration. Another contribution [Quit1], which has been done partly under this project, to the general understanding of QoS is this application-oriented high-level interface to the RTFM architecture that simplifies configuration by hiding several details and that thereby facilitates the integration of standardised traffic measurements into management applications. The simplification leads to a restriction of the available functionality. However, the remaining functionality still matches the requirements of a large range of management applications. Besides several simplifications, also one extension is contained in the suggested interface. The RTFM architecture requires a reader of measurement data to poll for new information. This pull mode is extended by a push mode creating notifications if new traffic data is available. The suggested interface has been implemented and tested to several projects prove its usability.
The RFTM architecture [RFC2722] defines components of traffic measurements systems and their interactions. Such components include a meter collecting traffic data, a reader obtaining data from the meter for further processing, and a manager, which configures meters and readers. Each meter observing a stream of packets contains a programmable packet-matching engine, deciding what to do with observed packets. Now, traffic is specified by providing code for the engine. Available instructions, called rules, include matching conditions for single fields of the packets, conditional jumps, etc.
A set of rules specifies one or more to be metered. A meter may contain several rule sets with each of them being executed for each observed packet. While this is powerful method, the task of specifying traffic-creating rule sets is also non-trivial and potentially complex. If someone wants to perform precise and elaborated measurements of a network, it is appropriate and acceptable to develop a rule set matching your requirements manually in a few hours or a few days. However, if traffic measurement is only one component of a large management system and especially, if the measurement task is to be configured dynamically, then the procedural specification by rule sets is no longer adequate. The complexity of this specification requires an - in many cases unacceptable - high effort and it makes this task highly error-prone. Both UCL and NEC observed this shortcoming of the RTFM architecture independently in several projects, where traffic measurements were to be integrated into management applications. In each of these projects, we solved the problem by developing a high-level abstraction layering. As a result, the particular management application sees exactly the required functionality and the rest of the complexity is hidden. After doing this several times at both places we decided to jointly use our experiences for developing a more general abstraction of the RTFM architecture. This interface should meet almost all of the requirements of management applications for which we had built abstractions and it should still be simple enough providing easy integration of traffic measurement into those applications.
[Quit1] outlines this interface and two of its implementations. It discusses also management applications requiring traffic measurements, and a set of requirements for the interface is derived from those applications. Based on these requirements, two implementations have been done in Java.
As a result of our experiences, we present an application-oriented high-level interface to the IETF RTFM architecture. It simplifies the integration of traffic measurement into network and service management applications. The interface replaces the complex procedural model of the RTFM architecture by a much simpler declarative one. Furthermore, it hides several details of the RTFM architecture. Applications using our interface are able to control traffic measurements easily at a high level of abstraction. Still, they have sufficient functionality available. They can collect measured data either in pull or push modes. The feasibility of the interface has been proven by the independent implementations. The use of those implementations in different projects also proved, that the interface is sufficiently generic for a wide range of applications.
3.4. Lower than Best Effort: a Design and Implementation
Most of the effort in QoS has been to achieve optimal Quality, with Better-than-Best-Effort (BBE) services, in the form of reserved resources for specific purposes. However to get the most of QoS optimisation, it is important to ensure that those applications that do not require it can opt for lower QoS. Another activity has been addressing just this problem. In a detailed design [Carl], in a direction that is missing in today's work on service models, we define schema used to purposely degrade certain traffic to various levels below that of Best Effort (BBE). In a sense, this provides a balancing effect in the deployment of BBE service. This is particularly evident with continual and parallel short transaction (like that used for web applications) over low bandwidth links that are not subject to any back-off penalty incurred by congestion because state does not persist. In a more indirect perspective, our model correlates degraded service with the application of usage and security policies (administrative decisions that can operate in tandem or disjointedly from conditions of the network). This activity addresses these and other issues and presents the design and implementation of such a new degraded service model and queuing mechanism used to support it.
The default service model of the Internet, known as Best Effort, is based on the design principle that a network does not set aside or reserve resources in forwarding data packets hop-by-hop to their destination. Failure in delivery can occur when resources along a path are exhausted or when there are breaks in connectivity. In recent years, the IP service model has been augmented; the network can provide Better-than-Best-Effort service, in the form of reserved resources. To date, this augmentation has been realised in two different sequentially developed efforts. The first, known as Integrated Services, is realised as either Control Load [RFC2212] or Guaranteed Service [RFC2211]. The former focuses on bandwidth levels, and the latter addresses bandwidth and delay bounds. Two important features of this new service are that its original design is based on a relatively granular scope (Source, Destination, Port tuple), and that the service is meant to be instantiated on an end-to-end basis. In order to achieve this service, the Internet Engineering Task Force (IETF) defined a resource reservation signalling protocol titled RSVP [RFC2475]. This protocol acts as a conduit for propagating reservation requests via an exchange of sender initiated Path messages, and corresponding receiver initiated Resv messages. In using RSVP to install the end-to-end attributes of a flow, state is not stored in the packet header, but installed in routers along the source-to-destination data path by an out-of-band signalling mechanism.
A different model was introduced into the IETF, DiffServ [RFC2475 takes a more abstract and local view on resource allocation. Specifically, it focuses on service agreements regarding bandwidth and/or delay between neighbouring routing domains. A separate entity, e.g., Bandwidth Broker, can be used to alter the scope of the agreement so that resources can be set aside to support changes in overall aggregate levels of traffic. Per Hop Behaviours can be used to help determine the scope and subsequent changes of the agreement between two domains. One distinctive aspect of this service model is that the characteristics of ingress traffic are compared against a pre-established profile. The profile represents the service level used by the next-hop transit domain to accept data for forwarding. If the ingress traffic does not conform to the profile, it is marked accordingly. The marked packet is placed in a virtual 'penalty box' and is then either dropped, or marked with lower precedence and forwarded to the next hop. This form of degraded service involves a binary decision process that is dependent on the congestive state of a node - i.e., degraded service only occurs with out-of-profile traffic and with no consideration of previous history of a non-conformant flow.
A complementary effort used to achieve Better-than-Best-Effort service is realised through the various queuing mechanisms that have been developed over the last several years. Two of the more notable designs have come in the form of Class Based Queuing (CBQ) [Floy2] and Weighted Fair Queuing (WFQ) [Dem]. CBQ defines classes, assigns a queue per class of traffic, and sets aside resources in an a priori manner to each class.
Independent of the scheduling of traffic, Random Early Detection (RED) was designed as a congestion avoidance mechanism that can complement a queuing mechanism. It uses a weighted moving average of queue size to determine when it should randomly drop a packet. Weighted RED is an extension that places pre-selected weights in prioritising the dropping of certain types of traffic [Lim]. The coupling of RED with per-flow queuing follows the attempt by researchers to support the classic notion of fairness with respect to best effort service, in that all users obtain an equal share of network resources.
This work shows how fairness can be achieved by using appropriate per-flow information. Until now, weights were the only means by which selective bias, a type of administrative policy, could be supported by queuing. However, these weights are static in nature, in that their selection is decided independent of changes in types of traffic, network usage, and security conditions. The importance of usage policies can be seen in the need to control unrestricted use of applications that are capable of bypassing the fairness supported by TCP and per-flow queuing. This is particularly acute in networks that are saturated with traffic, or are constrained by relatively low bandwidth links to other networks. Reliance on differentiated services to re usage policy can be problematic because of the limited number of code points that can be manipulated by downstream transit providers; e.g., Assured Forwarding (AF) provides 4 traffic classes, with 3 levels of Drop Precedence per class. Hence, in the case of where traffic traverses multiple transit providers, subsequent provider/DiffServ regions may need additional per-flow accounting in order to provide a lower schedule class than that which can be marked in a packet. There is a dynamic to adaptive TCP-like in that one cannot just consider what capacity is available now, but what share a given (class) is currently using, and will continue to use in the future. In other words, in cases like parallel short transactions that occur successively, a punishment/penalty box cannot effectively penalise unless some accounting state persists.
To achieve a more dynamic support of usage policies by the network as well as address gaps in supporting fairness, we propose the integration of per-flow accounting within a queuing mechanism. From this accounting, various levels of service can be applied per-flow, regardless of whether a single FIFO queue, or multi-queue, mechanism is used. These levels can re degraded or upgraded service and can be subject to monetary considerations (e.g., lower price correlating to a more restrictive policy), as well as security conditions. By this latter example, we mean that the level of confidence that a flow represents a security breach (e.g., in the form of denial of service) could be directly proportional to the degree that a usage policy penalises a flow.
A consequence of using policy and security criteria to degrade service within a queuing mechanism is that non-work-conserving behaviour may exist. But this is understandable given that security and administrative policy are orthogonal to fairness and congestion. A general and modular design that can support various algorithms and usage policies is presented. In addition an initial implementation is described of the design, termed Persistent Class Based Queuing (P-CBQ), that represents the integration of per-flow accounting to per-flow class queuing. Finally, we present experimental results using one particular set of penalty algorithms.
The design of a per-flow accounting mechanism to support degraded service through represents a new direction in the treatment of flow traversing a node. Three motivations behind this involve a desire to support usage policies, control for continual and parallel short transaction connections, and a need to degrade service for DiffServ packets whose priority has been set to the lowest value possible by previous entities/domains.
The resources of penalised are made available to other flow of a given class, or other classes of traffic, traversing the node. The fact that we accumulate information on subsequent flows allows us to penalise short-transaction flows like those generated by series of HTTP requests. Depending on its deployment and configuration, the amount of potential state makes our initial implementation more attractive at the leaf edges of networks. However, future work in aggregating penalty will allow us to apply our approach to the Internet as a whole.
A related feature involving our approach in degrading service is that the rate and severity of the penalisation process can be applied to discouraging user behaviour, in the form of continual and prolonged usage, of a given application. Coupled with an economically based charging model, one has the potential of charging for maintaining Best Effort service to avoid restrictive usage policies placed on applications like web browsers.
Our initial results have been based on a single penalty algorithm based on packet counts. This algorithm operates independent of existing end-to-end control algorithms, the rate at which packets are serviced/forwarded through a node, and uses a probabilistic means of determining whether a packet is to be dropped. Applied to UDP without control applied to upper level RTP packets, the PC type of algorithm allows us to incur a relatively smooth degradation of service upon a flow. However, an area that will require additional investigation and research involves the development and refinement of penalty algorithms that take into account the control algorithms inherent in TCP.
4. Internet Drafts
In addition to the specific publications on QoS, there have been a number of Internet Drafts. These include the following:
[Bris] Briscoe, R and J Crowcroft:” Open ECN Service in IP layer”, draft-ietf-tsvwg-ecn-ip-00.txt, Feb 2001.
[Crow3] Crowcroft, J and K Carlberg: “MAPEX, Application level multicast architectural Requirements for APEX, draft-crowcroft-apex-multicast-00.txt, February 2001.
[Quit2] Quittek, J and M. Pias: “A high-level application-oriented interface to the traffic flow measurement architecture”, draft-quittek-rtfm-generic-interface-00.txt, April 2001.
4.1. Open ECN Service
[Bris] contributes to the effort to add explicit congestion notification (ECN) to IP. In the current effort to standardise ECN for TCP it is unavoidably necessary to standardise certain new aspects of IP. However, the IP aspects will not and cannot only be specific to TCP. This contribution specifies the interaction with features of IP such as fragmentation, differentiated services, multicast forwarding, and a definition of the service offered to higher layer congestion control protocols. The document only concerns aspects related to the IP layer, but includes any aspects likely to be common to all higher layer protocols. Any specification of ECN support in higher layer protocols is expected to appear in a separate specification for each such protocol.
This document includes the necessary words to ensure that interactions with more aspects of the IP layer have been specified than in previous Internet drafts. It is believed that every aspect of this document is additive to [Rama]. The ability to define new marking behaviours and new host behaviours has been added using the DiffServ architecture. This has been achieved without affecting the behaviours already defined for TCP. Similarly, a forward-looking approach to fragmentation has been defined.
A stake has been placed in the ground warning that multicast duplication of ECN may not be as straight-forward as some believed, and allowing room for experimentation. Finally, requirements have been set to ensure that all new standardisation work will promote the use of ECN in preference to loss as a congestion signalling mechanism.
4.2. MAPEX
[Crow3] presents an approach to do application-layer multicast. It presents a design that produces a tree distribution structure within the existing design structure of APEX and BEEP. The design is not intended to replace multicast at the network layer. Where the need exists (and in scenarios where it would seem symbiotic), it is constructive to integrate the two technologies and perspective (i.e., application-layer and network layer multicast).
We conclude that we need some APEX topology and group management protocol elements:
· join/leave messages, with metrics
· group distribution/revocation
· "link" state advertisement/flood - top down on hops, bottom up on other metrics
We need some tree building code: basically Dijkstra (or incremental Dijkstra if you prefer), plus RPF code. Our preference is to retain a measure of simplicity in the initial tree construction that allows us to take advantage of the alternative paths available from a link- state algorithm.
We may want to allow for native IP multicast in stub domains. The natural question that arises is: what is the protection against loops between native multicast at the network level and application level multicast. This may have additional implications with respect to scoping -- possibly setting TTL scopes for intra-domain distribution, and yet assigning a set of multicast addresses for inter-domain APEX distribution.
Another issue that probably needs to be addressed is the issue of NATs. It may be a case of using NAT boxes as APEX gateways between native (TTL scoped) multicast at a source/destination domain, and TCP unicast distribution of APEX.
There are some further Questions to Consider:
· On whether MAPEX should be aware of lower level topology, we believe it should just be aware of the server topology.
· On whether MAPEX should be aware of lower level considerations like AS boundaries, we feel that APEX is naturally "aware" of the domain boundaries, but not the more abstract (or aggregated) level of AS boundaries.
On whether there are other application-level approaches to consider than a combination of link-state advertisements and YAM, Yallcast [Fran] and Application Level Active Networking (ALAN) [Nar], [Fry] are important
4.3. Traffic Flow Measurement API
[Quit2] specifies a high-level application-oriented interface to the Real-time Traffic Flow Measurement (RTFM) Architecture. The abstract interface models the RTFM architecture while hiding many of the details not relevant to an application programmer who want to integrate IP traffic measurements into an application. Particularly the interaction between manager, reader, and meter is hidden by the interface, and rule sets used for traffic measurement specification are replaced by simpler data structures. Furthermore, the RTFM interface supports complex actions like modifying a traffic measurement specification while it is already being applied. The interface is defined in an abstract way. It can be implemented by an application-programming interface as well as by a network protocol. Several security issues must still be considered if this interface is implemented by a network protocol. A fuller account of this work has been given in Section 2.3.
5. Recent Work on Virtual Private Networks and Other Active Services
We expect to return to our collaboration with ISI in time for the next joint demonstration in November 2001. In the mean time, we have concentrated on developing further the UCL components. We have been concentrating on a dynamic VPN scenario; it uses Cisco routers, their VPN Connector software to set up VPNs, a certificate generator/depository from Entrust, a network management system from Compaq with an Active VPN manager, Active Servers based on the FunnelWeb software and extensions of the Reflector software proxylet (RP) described in Section 4. It is used to set up a dynamic VPN to allow conferencing to be carried out in a closed user group using real management policies.
A schematic of the system that has been set up is shown in Fig. 4. This system was set up partly for another project, which involved Compaq. The Active Server (AS) and the Compaq Manager (CM) runs their system TeMIP above the FunnelWeb system. We have defined simple policies in XML, which can control the operation of the RP proxylet in the AS and the management operations in the CM. In this example, the Mbone tools merely generate traffic; they have not been modified for the active operations. The RP provides application transparency, and is an element that can be extended for active operation. The policies run in the CM. It is this system that is being extended for the future RADIOACTIVE work.
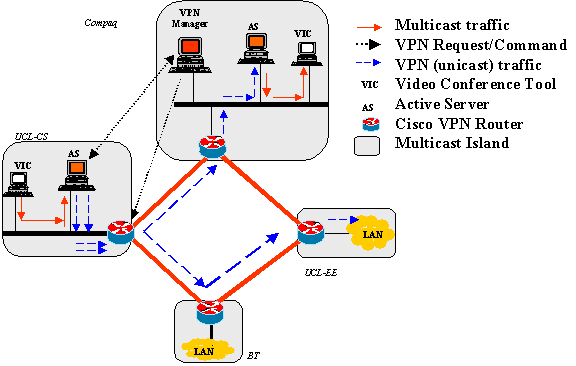
Figure 4 Schematic of Dynamic VPN experiments
We have set now up a pseudo manager (PM) to replace the Compaq VPN Manager in Fig. 4; it is this system that is being used in the on-going work. At present, we have an ability to demonstrate the capability of the Reflector and its operation in the presence (or lack thereof) of participants in a group communication session. The pseudo-manager acts as a test program that communicates and exchanges XML events between the various Reflector Proxylets operating at different sites. UCL has done some internal testing amongst 3 different LANs, as well as testing over the Internet using CAIRN nodes in the U.S. We will add the policy managers into both PM and RP. The dynamic set-up and control of the VPNs will then be controlled by XML policies. The Compaq TeMIP had the ability to control normal Cisco routers; our PM does not have this capability. We will use FreeBSD routers in this role.
We have developed a more powerful Transcoding Active Gateway (TAG), which will be used as the main component of the system of Fig. 4. This proxylet will not have the same data-driven activation as the Reflector proxylet, it will demonstrate the ability to load a proxylet onto an active server in order to extend multicast sessions over a unicast path. It will be extended to have additional functionality:
· Transcoding data streams from one media type to another
· Access to Web-based session store of announcements
· IPv6 support
In addition we expect to integrate it with XBone support and support for reliable data streams (as needed to extend the Mbone tools supported to include WBD.
6. Migration to IPv6
We intend to migrate our whole system to IPv6 as soon as practical. During the last six months, there have been further developments to ease this process. Solaris 8 has good IPv6 support; Windows 2000 now has proper IPv6 support versions of IPSEC for IPv6 Linux have come from IABG, and an early version of IPv6 support for JAVA have become available. For this reason, we have been slowly adapting our systems to move to IPv6 as soon as we can.
Our first step has been to ensure that all our main components are IPv6-enabled. This means that we have re-visited our implementations of RAT (audio), VIC (video), NTE (shared editor) and WBD (shared whiteboard). All seem reasonably stable and IPv6-enabled on the Windows 2000, Solaris-8, FreeBSD v3.4 and Linux xxx stacks. We have also ensured that the Secure Conference Store (SCS) runs on an IPv6-enabled Apache Server. SCS allows secured conference announcements to be made, and download announcement Proxylets that start up the Mbone tools.
We have started investigating the use of the early release of the Java JDK 1.4. This now contains IPv6 support, and should allow all our active network activity to be migrated.
7. Use of Resources
7.1. Staffing
While the funding from DARPA under the RADIOACTIVE Project has funded some of these activities, it has not been a very high proportion. This is partly because the project is only funded for one research student.
The UCL staff associated with the RADIOACTIVE project has been:
· Jon Crowcroft - Co-PI
· Peter Kirstein - Co-PI
· Herman de Meer - long term research
· Tom Lodge – providing the virtual manager for the VPNs
· Ken Carlberg – doing much of the design on the VPN demonstrator
· Piers O’Hanlon – developing the integration with the XBone
· Panos Gevros – working on the QoS activity
We also thank Prof. Michael Fry and Atanu Ghosh for their work on FunnelWeb and the whole EEPS software. During 2000/2001 the work has been co-funded by British Telecom under the ALPINE project, and we expect this to continue during 2001/2002.
Almost exactly at the end of this first year, the European Union funded project, ANDROID, started; this will provide end system applications, and will apply the ideas to mobility amongst other things. We expect to work further with Joe Touch at ISI in deploying EEPs over the XBone technology. To this end, we are always running an EEP on our CAIRN infrastructure at UCL.
7.2. Travel
During the last year, funds from RADIOACTIVE have helped defray expenses for attendance at IETF, IRTF Reliable Multicast and End2end groups. It has also helped finance attendance at SIGCOMM and DARPA PI Meetings.
References
[Bris] Briscoe, R and J Crowcroft:” Open ECN Service in IP layer”, draft-ietf-tsvwg-ecn-ip-00.txt, Feb 2001.
[Carl] Carlberg, K, P Gevros and J Crowcroft: “Lower than Best Effort: a Design and Implementation”, Workshop on Data Communications in Latin America and the Caribbean, 3-5 April 2001 San Jose, Costa Rica.
[Chiu] Chiu, D and R Jain: “Analysis of the Increase and Decrease Algorithms for Congestion Avoidance in Computer Networks”, Computer Networks and ISDN Systems, 17, 1, 1-14, 1989.
[Crow1] Crowcroft, J et al: “DARPA Radioactive Project, First Annual Technical Report”, Department of Computer Science, University College London, October 2000.
[Crow2] JCrowcroft, J et al: “Mechanisms for Supporting and Utilising Multicast Multimedia-SCAMPI, Proposal to DARPA for an extension to D079”, Principal Investigators Jon A. Crowcroft and Peter T. Kirstein, Department of Computer Science, University College London, June 1999.
[Crow3] Crowcroft, J and K Carlberg: “MAPEX, Application level multicast architectural Requirements for APEX, draft-crowcroft-apex-multicast-00.txt, February 2001.
[DeMeer] De Meer and P. O'Hanlon: “Segmented Adaptation of Traffic Aggregates”, to appear in IEEE IWQoS 2001.
[Demer] Demers, A et al.: “Analysis and Simulation of a Fair Queueing Algorithm". In Proc. ACM SIGCOMM, pp 1-12, Austin, Texas, Sept. 1989.
[Floy1] Floyd, S and V. Jacobson: “Link-sharing and Resource Management Models for Packet Networks". IEEE/ACM Transactions on Networking, 3(4):365{386, Aug. 1995.
[Floy2] Floyd, S. and K. Fall : Promoting the Use of EndtoEnd Congestion Control in the Internetj; IEEE/ACM Transactions on Networking, Vol. 7(4):pp. 458–473, (August 1999).
[Fran] P Francis: “YALLCAST arhictecture”, http://www.aciri.org/yoid/docs/index.html.
[Fry] M.Fry et al: “Application Level Active Networking'', Fourth International Workshop on High Performance Protocol Architectures (HIPPARCH '98), June 98.
[Gevros] Gevros, P et al: “Congestion Control Mechanisms and the Best Efforts Service Model”, To Appear in IEEE Networks, 2001.
[Ghosh] Ghosh, A., M. Fry and J. Crowcroft:”An Architecture for Application Layer Routing”; Yasuda, H. (Ed), Active Networks, LNCS 1942, Springer:pp. 71–86. ISBN 3540411798 SpringerVerlag, (October 2000).
[Hang] [http://www.cs.cmu.edu/~hzhang/multicast/rm-trees/.
[kirs] Kirstein, PT, E Whelan and I Brown: "A Secure Multicast Conferencing", DISCEX 2000, pp 54-63, IEEE Computer Society, 2000.
[Lin] Lin, D and R. Morris. "Dynamics of Random Early Detection", Proc. SIGCOMM, pp 127-137, Cannes, France, 1997.
[Nar] Narada: “Application level multicast”, CMU,
[Quit1] Quittek, J, M Pias, and M Brunner: “Integrating IP Traffic Flow Measurement”, In IEEE Open Architectures and Network Programming (OpenArch'01), Conference, April 2001, Anchorage(Alaska). http://www.cs.cmu.edu/~hzhang/multicast/other/endsystem-index.html.
[Quit2] Quittek, J and M. Pias: “A high-level application-oriented interface to the traffic flow measurement architecture”, draft-quittek-rtfm-generic-interface-00.txt, April 2001.
[Rama] Ramakrishnan, K et al.: “The addition of explicit congestion notification (ECN) to IP. IETF, http://www.ietf.org/internet-drafts/draft-ietf-tsvwg-ecn-01.txt, January 2001. (Work in progress).
[Real] [http://www.real.com/].
[RFC2211] Wroclawski, J: “Specification of the Controlled-Load Network Element Service”, . http://www.ietf.org/rfc/ 2211, IETF, Sept. 1997.
[RFC2212] Shenker, S et al.: “Specification of Guaranteed Quality of Service". http://www.ietf.org/rfc/rfc2212, IETF, Sept. 1997.
[RFC2475] Blake, S., D. Black, M. Carlson. E. Davies, Z. Wang, and W. Weiss: “An Architecture for Differentiated Services”, http://www.ietf.org/rfc/rfc2475.txt, December 1998.
[RFC2722] Brownlee, N, C Mills and G Ruth, “Traffic Flow Measurement: Architecture," http://www.ietf.org/rfc/rfc2722.txt, October 1999.
[RFC2723] Brownlee, N, “SRL: A Language for Describing Traffic Flows and Specifying Actions for Flow Groups," http://www.ietf.org/rfc/rfc2722.txt, October 1999.