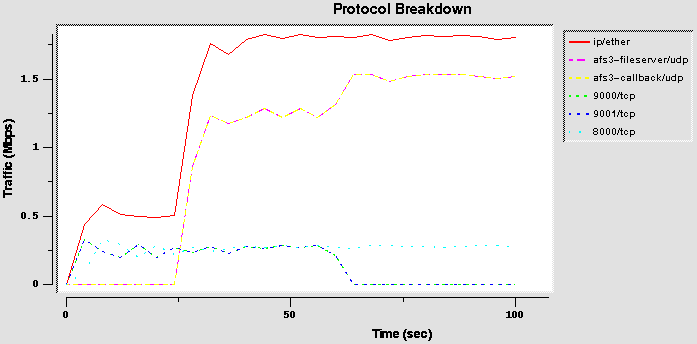
ALTQ Package – CBQ Testing
The goal is to test the ALTQ package to understand the impact on new forms of scheduling (primarily CBQ) on the router performance and on traffic management.
- Test environment
The main test environment consists of two PC running Unix BSD connected with an ATM 155Mbps link: one runs the CBQ daemon and the other acts as a network capture.
The TTCP package is used as Traffic Generator: this program runs on the Windows 95 machine or on the same machine of the CBQ daemon. This double location is basic because the switched Ethernet between the Win95 machine and the CBQ can affect the results in high bandwidth tests.
The TTT package is used as traffic monitor, in certain cases running directly on the second BSD machine, in certain others running the TTTProbe on the BSD machine and the TTTView on the Solaris machine. Since the TTT graphical interface uses a lot of CPU resources, the second option is used to avoid a CPU overload when running some high bandwidth tests.
|
Name |
Machine Type |
Network |
OS |
Other Packages installed |
Task |
|
Kirki |
AMD K6/200, 64MB RAM |
1 Ethernet 10Mbps, 1 ATM 155Mbps
PVC setting: At various speed (generally between 1 and 10 Mbps) |
UNIX BSD 2.2.7 |
ALTQ 1.1.1
TTCP (recv)
TTT
TTTProbe |
Network Capture; in certain cases also Network Monitor |
|
Ammon |
Intel P166, 32MB RAM |
1 Ethernet 10Mbps, 1 ATM 155Mbps
PVC setting: At various speed (generally between 1 and 10 Mbps) |
UNIX BSD 2.2.7 |
ALTQ 1.1.2
TTCP (send) |
CBQ daemon
In certain cases, also Traffic Generator |
|
Thud |
Sun Sparc 5 |
Ethernet 10Mbps |
Solaris 2.5.1 |
TTTview |
Network Monitor |
|
Truciolo |
Intel PII-266 |
Ethernet 10Mbps |
Windows 95 |
TTCP (send) |
Traffic Generator |

- Static tests
Static tests help to discover the static behaviour of the CBQ package. Main goals are:
- the correctness of the class allocation imposed
- the class isolation (the traffic in one class must not affect the other)
- the correctness of the classifier mechanism
- Bandwidth class allocation tests
These tests show the granularity of the classifier. Results show that:
- a class with 0% receives no service: the CBQSTAT program reports a minimum bandwidth share of 34.20 Kbps, but in our test with a 10Mbps root class bandwidth all packets belonging to this class has been discarded by the CBQ daemon without regard to their payload size
- the classifier ignores fractionally bandwidth shares (1.2%, i.e.), truncating the decimal part; in this way a class with 0.6% receives no service at all
- by default (and for compatibility with earlier release) if not explicitly differently specified the CBQ daemon allocates 2% of the total bandwidth to the Control Class (ctl_class), used to carry control traffic (ICMP, IGMP, RSVP)
- the precision of the CBQ output rate can have error margins of several percent against the real interface speed
Finally, the CBQ root bandwidth set in the configuration file and reported by CBQSTAT program is:
- the IP and the link layer overhead if the CBQ is running on an Ethernet interface
- the IP bandwidth if the CBQ is running on an ATM interface.
So, configuring the CBQ at full speed on an Ethernet interface requires setting the root class bandwidth to 10.000.000 bps; vice versa configuring the CBQ to an ATM interface whose PVC is set to 2Mbps (with the PVCTXCTL command, that it reports an effective connection of 5139 cell/s) the root class bandwidth needs to be set to 5139*8*48= 1973376 bytes.
At the moment it is not clear (to me) if the AAL5 and LLC/SNAP is included in the ATM header (so the root bandwidth includes the AAL5 and LLC/SNAP as well) or not. However, for CBQ purposes, high precision is not important: the calculation of the true value of the root class bandwidth is not of interest.
[Tests: class_allocation.*]
To understand the test results details
The analysis of these test results need to remember:
- the protocol header overhead: for ATM we have the ATM header (5 bytes), AAL5 envelope (8 bytes), LLC/SNAP envelope (8 bytes), IP header (usually 20 bytes), TCP/UDP header (respectively 20 (usually) and 8 bytes)
- the ATM MTU is 9180 bytes. If not differently specified, the UDP flow generally makes packet based on the UDP payload length, while TCP flow bufferises the data until it can send a packet with the MSS length (or with the socket buffer length, if this value is less than the MSS). In these test the socket buffer length is usually equal to 8192
- in all tests there is the "hidden" control class, that impacts 2% of the total bandwidth. In other words with a root class bandwidth of 2Mbps we have 40Kbps wasted due to the control class settings
The following table explains the main parameters reported in the test results.
|
Test Characteristics
|
PVC Settings |
Traffic Type |
Throughput
TCP/UDP (KB/s) |
Estimated Throughput |
TCP/UDP payload |
N° buf sent |
|
IP (Kbps) |
ATM (Kbps) |
ATM (cell/s) |
|
A brief summary of the test configuration: classifier filters and class configuration |
The PVC hardware setting (with PVCTXCTL command) |
A brief summary of the flow involving the test, with the classes they belong to |
Throughput reported by TTCP program. It corresponds to the level 4 throughput (total UDP/TCP traffic divided by the time). It doesn’t include any level 3 (and below) headers |
IP (Kbps): is an estimation of the IP traffic, considering all generated packets with a fixed dimension (based on the TCP/UDP payload)
ATM (Kbps): is the corresponding ATM bandwidth estimate, based on this fixed IP dimension
ATM (cell/s): is an estimation of the number of ATM cell/s |
Dimension of the TCP/UDP payload. For UDP traffic this is the base of the IP packet construction; for TCP traffic it is not correct because:
1. by default TCP bufferises the data and sends it only when it reaches the MSS
2. the sliding window mechanism force, some time, to send a packet with smaller dimension |
Is the number of writing on the underlying socket. Timed by the previous parameter, it represents the number of bytes transmitted |
In some test it has been used a PVC with different bandwidth (PVCTXCTL command) settings but always with the same root class bandwidth. In brief, these are the real values regarding the different settings:
- 2 Mbps: it corresponds to 1.973 Kbps, 5139 cell/s
- 3 Mbps: it corresponds to 2.884 Kbps, 7512 cell/s
- 10 Mbps: it corresponds to 9.835 Kbps, 25614 cell/s
Summarizing the test characteristics:
- test program: TTCP
- test duration: is determined when all flow finishes, basically when all data (TCP/UDP payload times n° buf sent) has been sent.
- the only "certain" throughput is the TCP/UDP one. Other throughputs are estimations and they are quite accurate for UDP traffic only
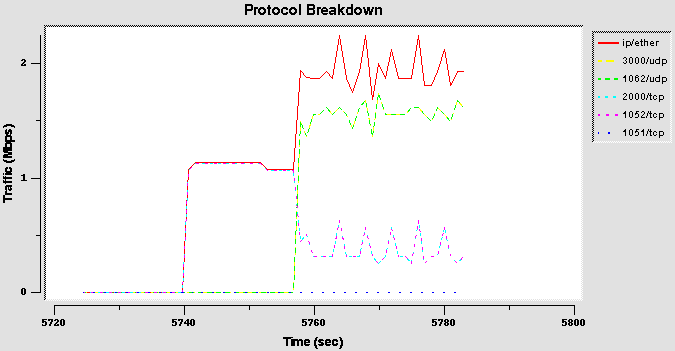
- Classifier and bandwidth share tests
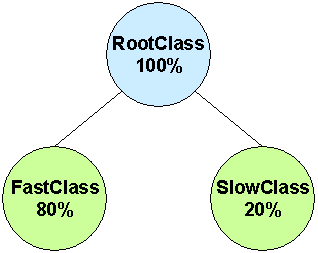
This test suite has a very simple configuration: a root class of 2Mbps has two leaf classes with an 80% and 20% share. Classes are isolated: anyone is allowed to borrow from the root class.
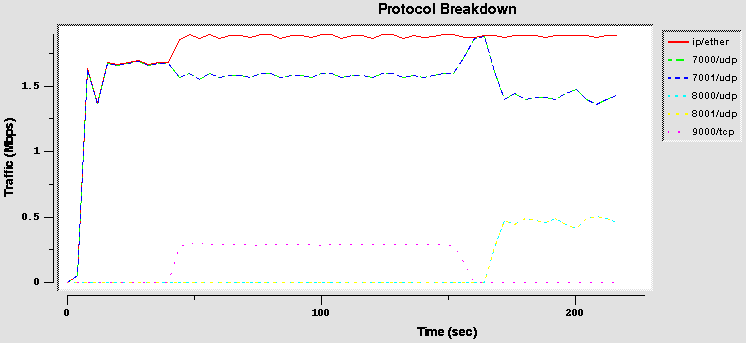
Bandwidth share test: configuration 1 (proto)
This test uses a very simple classifier (on protocol type), with mixed TCP and UDP traffic.
|
Test Characteristics
Classifier Filter:
Protocol Type
Class Definitions:
0. Root Class (100%, 2 Mbps)
A. Slow Class: UDP (20%)
B. Fast Class: TCP (80%) |
PVC Settings |
Traffic Type |
TCP/UDP
Throughput (KB/s) |
Estimated Throughput |
TCP/UDP payload |
N° buf sent |
|
IP (Kbps) |
ATM (Kbps) |
ATM (cell/s) |
|
Name: Tcp
|
2 Mbps |
A: --
B: TCP |
--
166.32 |
--
1369.15 |
--
1480.64 |
--
3492.08 |
--
8192 |
--
2048 |
|
3 Mbps |
A: --
B: TCP |
--
166.20 |
--
1368.15 |
--
1479.56 |
--
3489.54 |
--
8192 |
--
2048 |
|
10 Mbps |
A: --
B: TCP |
--
178.88 |
--
1472.54 |
--
1592.45 |
--
3755.78 |
--
8192 |
--
2048 |
|
Name: Udp
|
2 Mbps |
A: UDP
B: -- |
47.83
-- |
393.16 |
425.80
-- |
1004.25
-- |
8192
-- |
2048
-- |
|
3 Mbps |
A: UDP
B: -- |
47.74
-- |
392.43
-- |
425.00
-- |
1002.37
-- |
8192
-- |
2048
-- |
|
10 Mbps |
A: UDP
B: -- |
47.76
-- |
392.59
-- |
425.18
-- |
1002.78
-- |
8192
-- |
2048
-- |
|
Name: Tcp-udp
|
2 Mbps |
A: UDP
B: TCP |
47.66
153.15 |
391.76
1260.74 |
424.28
1363.41 |
1000.67
3215.58 |
8192
8192 |
2048
8192 |
|
3 Mbps |
A: UDP
B: TCP |
47.41
166.92 |
389.71
1374.08 |
422.06
1485.97 |
995.43
3504.66 |
8192
8192 |
2048
8192 |
|
10 Mbps |
A: UDP
B: TCP |
47.57
170.21 |
391.02
1401.16 |
423.48
1515.26 |
998.78
3573.73 |
8192
8192 |
2048
8192 |
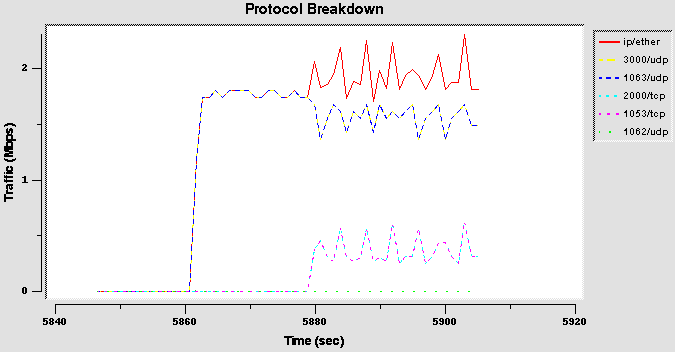
Bandwidth share test: configuration 2 (dport)
Basically this is the same test as before, but with the destination port field as the classifier filter.
|
Test Characteristics
Classifier Filter:
Destination Port
Class Definitions:
0. Root Class (100%, 2 Mbps)
A. Slow Class: d_port 2000 (20%)
B. Fast Class: d_port 3000 (80%) |
PVC Settings |
Traffic Type |
TCP/UDP
Throughput (KB/s) |
Estimated Throughput |
TCP/UDP payload |
N° buf sent |
|
IP (Kbps) |
ATM (kbps) |
ATM (cell/s) |
|
Name: Udp-udp
|
2 Mbps |
A: UDP
B: UDP |
47.39
161.46 |
389.55
1327.20 |
432.00
1471.39 |
1018.88
3471.39 |
8192
8192 |
2048
8192 |
|
3 Mbps |
A: UDP
B: UDP |
47.39
157.36
|
389.55
1293.50 |
432.00
1434.49 |
1018.88
3383.24 |
8192
8192 |
2048
8192 |
|
10 Mbps |
A: UDP
B: UDP |
47.55
161.62 |
390.86
1328.52 |
433.47
1473.33 |
1022.33
3474.83 |
8192
8192 |
2048
8192 |
|
Name: Udp
|
2 Mbps |
A: --
B: UDP |
--
167.18 |
--
1374.22 |
--
1524.01 |
--
3594.37 |
8192
8192 |
2048
8192 |
|
10 Mbps |
A: --
B: UDP |
--
167.32 |
--
1326.05 |
--
1470.59 |
--
3468.38 |
8192
8192 |
2048
8192 |
|
Name: Tcp-tcp
|
2 Mbps |
A: TCP
B: TCP |
46.79
154.51 |
385.18
1271.93 |
426.54
1408.51 |
1005.99
3321.97 |
8192
8192 |
2048
8192 |
|
3 Mbps |
A: TCP
B: TCP |
46.72
166.38 |
384.60
1369.64 |
425.90
1516.72 |
1004.48
3577.17 |
8192
8192 |
2048
8192 |
|
10 Mbps |
A: TCP
B: TCP |
46.70
172.69 |
384.43
1421.58 |
425.72
1574.24 |
1004.05
3712.84 |
8192
8192 |
2048
8192 |
|
Name: Udp-tcp
|
2 Mbps |
A: TCP
B: UDP |
46.78
167.84 |
385.09
1381.66 |
426.45
1530.03 |
1005.77
3608.56 |
8192
8192 |
2048
8192 |
Bandwidth share test: classifier behaviour (classifier)
Some tests have been repeated with different classifier settings to test if the classifier puts traffic in the right class.
|
Test Characteristics |
PVC Settings |
Traffic Type |
TCP/UDP
Throughput (KB/s) |
Estimated Throughput |
TCP/UDP payload |
N° buf sent |
|
IP (Kbps) |
ATM (kbps) |
ATM (cell/s) |
|
Name: tcp-tcp_saddr
Classifier Filter:
Source Address
Class Definitions:
0. Root Class (100%, 2 Mbps)
A. Slow Class: s_addr Truciolo (20%)
B. Fast Class: s_addr Kirki (80%) |
2 Mbps |
A: TCP
B: TCP |
39.77
163.62 |
327.39
1346.92 |
354.05
1456.60 |
835.01
3435.38 |
8192
8192 |
2048
8192 |
|
Name: tcp-udp_daddr
Classifier Filter:
Destination Address
Class Definitions:
0. Root Class (100%, 2 Mbps)
A. Slow Class: d_addr Ammon_ATM (20%)
B. Fast Class: d_addr Ammon_ETH (80%) |
2 Mbps |
A: UDP
B: TCP |
47.66
155.57 |
391.77
1280.65 |
424.29
1384.94 |
1000.67
3266.36 |
8192
8192 |
2048
8192 |
|
Name: tcp-udp_saddr_dport_proto
Classifier Filter:
Protocol Type, Source Address and Destination Port
Class Definitions:
0. Root Class (100%, 2 Mbps)
A. Slow Class: TCP, s_addr Truciolo, dport 2000, (20%)
B. Fast Class: UDP, s_addr Kirki, d_port 3000, (80%) |
2 Mbps |
A: TCP
B: UDP |
39.16
169.46 |
322.37
1394.99 |
348.62
1508.59 |
822.21
3558.00 |
8192
8192 |
2048
8192 |
Results
With these tests we have the following results:
- Class isolation
: is respected; results with TCP and UDP throughput are quite similar in all tests.
- Throughput
:
- TCP performs a little worse than UDP due to its fair behaviour, compared to the aggressiveness of UDP, despite the fact it usually sends bigger packets than UDP
- Anyway you can see bigger variations from the UDP and TCP throughput when they belong to the fast class than when they belong to the small class. The small class seems to be more "stable" (with less throughput variation) than the fast class
- Some variations can be seen in the fast class when changing the hardware PVC settings (from 2 to 10 Mbps) especially on the TCP flow, probably due to the different window management (increasing the PVC settings the traffic becomes more burstly and this could change the TCP window tempistics) (NOTE: ??)
- When computing the overall traffic it seems that not all the bandwidth has been used: the sum of the IP throughput referred to UDP flow (that allows a more affordable IP traffic extimation) is approximately 1380 + 390 = 1770Kbps, compared to approximately 2Mbps of the root class.
- Bandwidth share
: it seems that the slow class receives a a little more than the 20%, or, better, it seems that the fast class doesn’t receive all the 80% assigned. Anyway, this 20-80 share isn’t exactly respected: this result confirms that the main CBQ goal isn’t the absolute precision.
- Class allocation with different packet size (p_size)
The CBQ mechanism uses the "mean packet length" concept to determine how many packets must be forwarded in each class. The goal of the following tests is to show the CBQ class allocation when flows with different payload size (some time much smaller than the MTU) are sent to the router.
|
Test Characteristics
Classifier Filter:
Destination Port
Class Definitions:
0. Root Class (100%, 2 Mbps)
A. Slow Class: d_port 2000 (20%)
B. Fast Class: d_port 3000 (80%) |
PVC Settings |
Traffic Type |
TCP/UDP
Throughput (KB/s) |
Estimated Throughput |
TCP/UDP payload |
N° buf sent |
|
IP (Kbps) |
ATM (kbps) |
ATM (cell/s) |
|
Name: Udp -udp_l1024 |
2Mbps |
A: UDP
B: UDP |
36.08
161.77 |
303.65
1361.46 |
351.85
1577.58 |
829.84
3270.71 |
1024
1024 |
2048
8192 |
|
Name: Udp -udp_l512 |
2Mbps |
A: UDP
B: UDP |
30.05
136.42 |
259.63
1178.67 |
305.79
1388.21 |
721.20
3274.08 |
512
512 |
2048
8192 |
|
Name: Udp -udp_l256 |
2Mbps |
A: UDP
B: UDP |
22.28
117.87 |
202.48
1071.20 |
264.50
1399.35 |
623.84
3300.36 |
256
256 |
2048
8192 |
|
Name: Udp -udp_l128 |
2Mbps |
A: UDP
B: UDP |
15.21
92.00 |
151.86
918.53 |
206.37
1248.26 |
486.72
2944.00 |
128
128 |
2048
8192 |
|
Name: Udp -udp_l64 |
2Mbps |
A: UDP
B: UDP |
9.27
62.28 |
109.16
733.41 |
188.66
1267.52 |
444.96
2989.44 |
64
64 |
4196
16384 |
|
Name: Udp -udp_l32 |
2Mbps |
A: UDP
B: UDP |
5.45
37.66 |
83.71
578.46 |
147.89
1021.94 |
348.80
2410.24 |
32
32 |
8192
32768 |
|
Name: Udp-Udp_l32-512 |
2Mbps |
A: UDP
B: UDP |
30.18
36.91 |
260.76
566.94 |
307.11
1001.69 |
724.32
2362.24 |
512
32 |
2048
32768 |
Results
Results confirms that CBQ can be sensitive to the packet size, because it uses a "medium packet size" to compute the Idle parameter. Since, when AvgIdle < 0 the class is considered overlimit, if Idle is computed with the wrong packet size the AvgIdle become negative even if the class has transmitted less than its allocated bandwidth.
The CBQ, if not differently specified, sets its packetsize parameter to the MTU link layer, supposing that application tends to generate packets with the MTU length. However this is not true for all application, especially for multimedia audio packets, but for some TCP flows as well (it depends on the MSS).
This effect can be limited setting an appropriate packetsize parameter for a certain class in the CBQ configuration file; however this means that we must know in advance the medium packet size of the data carried in that class.
This graph reports the results of some different UCP flows, clearly showing the worsening. In this test UDP is more affordable than TCP because it is simpler to generate fixed size packets. With TCP flow there can be some window management problems: in certain cases the TCP throughput is considerably less than the UDP one (if the sockbuffersize is set to N bytes, TTCP –b option), or much bigger (if the TCP buffer sent is set to N byte, TTCP –l option, even with the Nagle algorithm disabled, TTCP –D option). Equivalent results to UDP performance can be seen with TCP flow if, after starting the CBQ daemon, the MTU size is reset to N bytes (where N is chosen carefully).
Other tests (not reported here) show that this bad behaviour can be avoided setting an appropriate packetsize parameter. Vice versa increasing the maxburst parameter has no effect because this parameter works on the weighted round-robin mechanism. In other word, increasing maxburst, the scheduler is able to send more packets only if the estimator permits this, i.e. only if the class is not overlimit. But, since choosing the wrong packetsize parameter the class becomes overlimit even if it has transmitted only a few bytes, clearly increasing the maxburst can not be effective.
- Dynamic tests
Dynamic tests help to discover the instantaneous throughput of each connections in the CBQ router. Basically, the main goal is to test the borrow mechanism that is very important in CBQ.
Being CBQ a non work conserving discipline, it can happen that some connections have a backlog and contemporary the output link is idle. This can be avoided by configuring the CBQ to use the excess bandwidth activating the "borrow" flag in some classes. In this way a class is allowed to borrow from its parent if the parent has unused bandwidth.
Clearly the behaviour of this mechanism must respect the bandwidth share imposed in the configuration files.
- Test configuration
We tested four configuration; all with the ATM PVC and the root class bandwidth of 4Mbps, except the third test that has the PVC and the root class of 2Mbps.
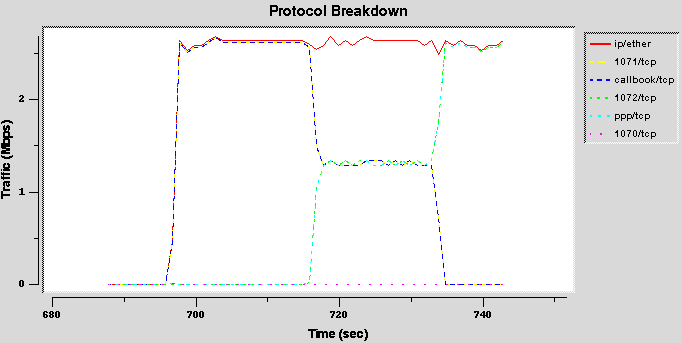
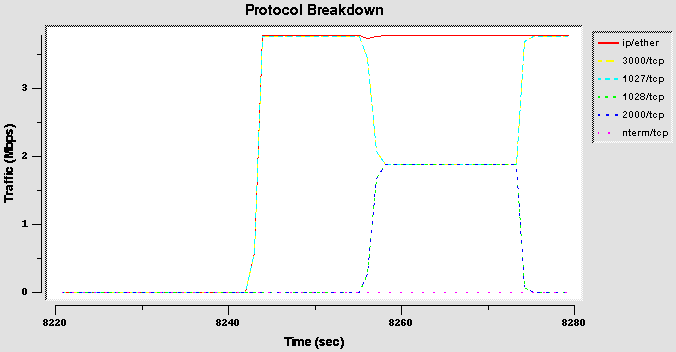
- Configuration 1 (borrow1)
In the first configuration a very simple test was used: two flows, one in the fast class and one in the slow class; the second flow starts some seconds after the first. The class configuration is very simple: only the leaf classes are allowed to borrow from it parent class.
The goal is to verify that when a class is idle the other is able to use all the parent bandwidth.
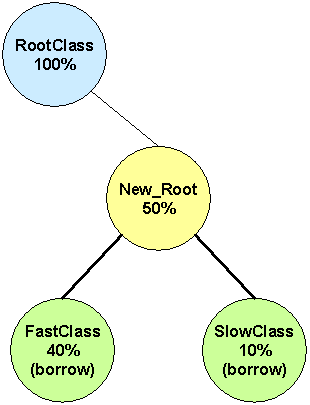
Results
The traces shows that, when both flows are active, the bandwidth share is correctly reserved. However, the slow flow is not able to use all the parent bandwidth when the fast flow is off. But, even if the fast class (when alone) is able to consume much more bandwidth than the small class it doesn’t use the total parent bandwidth: when both classes are concurrently transmitting the total traffic is a little bigger that the fast class traffic alone.
These traces are confirmed with different traffic patterns: TCP-UDP, UDP-TCP, TCP-TCP have the same result: if only one flow is present it is unable to use all the parent’s bandwidth, and this is more problematic for the slow_class flow, whose throughput is considerably less then the root bandwidth.
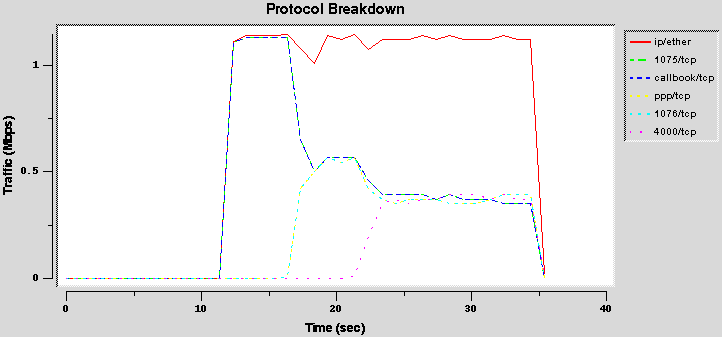
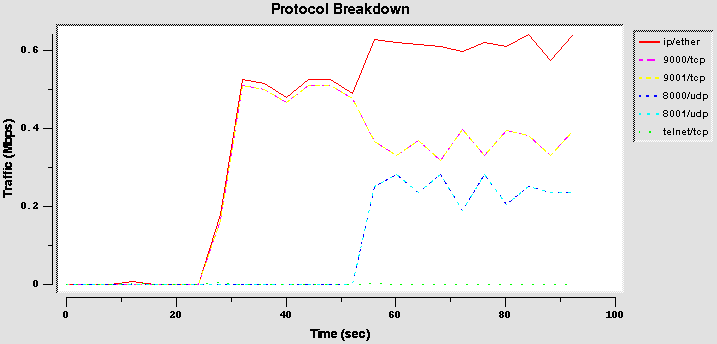
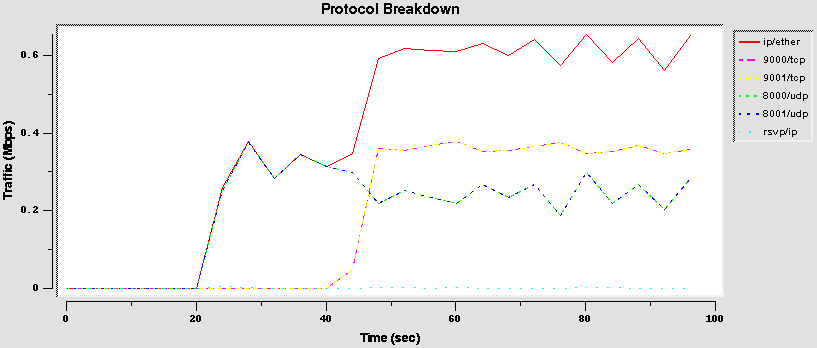
- Configuration 2 (borrow2)
This test involves three agencies, but only two flows are present. In this way the free bandwidth must be shared proportionally among the two active agencies.

Results
Results shows a different behavior from TCP and UDP. TCP flows (first three graphs) are not able to use well the borrow flag. Due to its "fair" behavior and to the CBQ characteristic to send packets in burst, if more than one TCP flow is sharing a link with the borrow flag it adapts each other. The result is that if three TCP flows are present, they share equally the bandwidth. The first graph reports the behavior with two flows (the agency1 and agency2) that share equally (50%) the link, and the second graph reports the behavior with all three flows, starting in different time: the bandwidth for the first flow is the 100% when only it is present, but drops to the 50% when the second flow starts, and to the 33% when also the third starts. The third graph shows, however, that if all three flows starts at the same instant, they initially have a differently throughput, but they adapt themselves quickly to share equally the bandwidth.
Vice versa, the UDP flows are able to share the bandwidth (fourth graph): the share is not exactly that imposed (10-40-50%), but anyway the three flows are able to transmit with different rate.
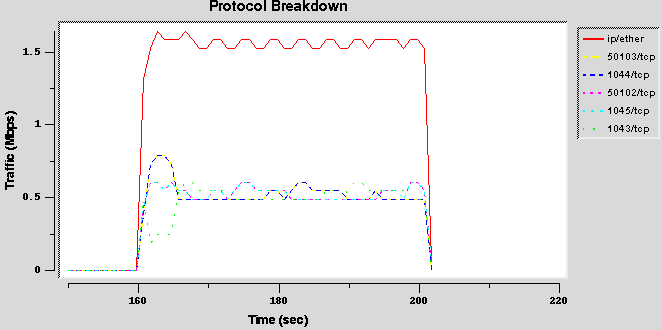
- Configuration 3 (rsvp)
This configuration uses the default configuration file for RSVP. RSVP creates leaf classes (Session1 and Session2) only and does not affect the behavior of the CBQ mechanism. For this reason these graphs can be seen as an example of the borrow flag without consider their RSVP origin. In this test, very similar to the previous one, the difference is that one flow has bigger packets than the other. Two flows have the same bandwidth allocation, but the UDP flow has 8192 bytes payload while the TCP one has 1460 bytes payload.

Results
These graphs show that the TCP session always receives a better service than the UDP one: these differences are more evident in the first two graphs. However there are no differences in the configuration regarding these four plots: so the different behaviour among them is not clear (NOTE: to me L
).
The better performance of TCP flows is due to the fact that the borrow mechanism does not work well if classes have different packet size. (NOTE: I’m not sure why).
Moreover, not the whole cntlload bandwidth is used from the two leaf classes. Borrow mechanism seems do not work so well with small classes.
- Configuration 4 (borrow3)
In this more complex configuration, each class is able to borrow from its parent. So leaf classes are able to borrow from the "agency" classes, and agency classes are able to borrow from the root class.
This can be a very common configuration in the real world because it is not useful to waste bandwidth: if this is possible (if there is unused bandwidth) is good to avoid any backlogged classes. The only way to avoid this is to permit all classes to borrow when other classes are idle, but this means that we have to be sure that the bandwidth share imposed for each agency will be respected.

Results
This test was performed with only two TCP flows, one in the agency1 slow class, and the other in the agency2 one.
Results show that the two TCP flows share the total bandwidth equally (4Mbps), despite their different agency share.
A similar result was obtained substituting the two TCP flow with one TCP and one UDP. Here results are more stranger, because:
- when no other flows are on, the TCP flow, belonging to the bigger agency, is able to use the total link bandwidth (differently from the previous test). Vice versa the UDP flow, belonging to the smaller agency, is not able to do this
- when both flow are on, the UDP flow bandwidth remains unchanged and uses more bandwidth than the TCP flow that vice versa, since it belongs to the bigger agency, it should get more service than UDP
Anyway, it seems that the borrow, that is essential in the real world, doesn’t permit to respect the bandwidth share between different agency.
More analysis on UDP flow (
borrow3b)
It’s very strange this UDP behavior, because even it the UDP flow has the same parameter of the TCP (same class, same packet size, …) it seems that with this particular class configuration it performs very bad compared to TCP.
To confirm this strange result, a new test involving 3 machines is done:
- Juliet, UDP source, is connected to Ammon via a 8Mbps PVC
- Ammon, the CBQ daemon (with the same class configuration as before) connected to Kirki via a 4Mbps PVC
- Kirki, the sink router
Results show that in this test UDP performance are even worse than it the previous configuration: while Juliet is sending UDP flow to approximately 6Mbps, Kirki is receiving the same flow at 1.5Mbps only, but the TDP flow reaches 3.5Mbps. All test are performed with only one flow in the system and all parameter are the same; TCPDUMP traces show that both UDP and TCP have the same packet size (so there are not smaller TCP packet due to some windows management, problem that appeared in previous tests).
Obviously, also the CBQSTAT report is the same: both flows reach the minidle parameter, and the only difference among them is that the UDP flow has always the queue full (30 packets), while the TCP flow usually has no packet in queue.
Performing a post elaboration on the TCPDUMP traces, it can be seen that the UDP flow on the sink router has higher variance compared to the TCP flow: this is not due to the source pattern, because a capture on the source router shows that here the variance is very small.
The following table reports the medium value, the standard deviation and the variance if the interpacket time among packets.
| |
Kirki (TCP) - sink |
Kirki (UDP) - sink |
Juliet (UDP) - source |
|
Medium value |
0.016878934 |
0.042618816 (1) |
0.008806352 |
|
Standard Deviation |
0.002360582 |
0.058480941 |
2.51813E-05 |
|
Variance |
5.56956E-06 |
0.00341658 |
6.33939E-10 |
(1) In this test the medium value has no much significance, because in effect the graph reports that the interpacket time is mainly concentrate around two values: 16.7 and 176 ms.
- CBQ with RSVP
CBQ can coexist with RSVP: when the RSVP daemon accept a new connection, CBQ dynamically creates a new class in its queuing hierarchy. The CBQ daemon starts automatically when the RSVPD is activated, loading the standard configuration file /etc/cbq.conf. ALTQ package suggests to set this default configuration file:
# CBQ configuration for RSVP
interface pvc0 bandwidth 2M cbq
class cbq pvc0 root_class NULL priority 0 admission none pbandwidth 100
class cbq pvc0 unres_class root_class borrow priority 3 pbandwidth 60 default
class cbq pvc0 res_class root_class priority 6 pbandwidth 40 admission cntlload
In other word only two class are defined, one for best effort and the other for reserved traffic. The latter is characterised by the keyword "cntlload", and is the parent class of all the reserved sessions. The suggested configuration allows only the best effort traffic to borrow from the root class (the same feature is disabled for the control_load class).
Reserved sessions class can belong only to the Controlled Load service: Guaranteed Service is not supported, and all sessions requiring a Guaranteed Service are refused (Error 21, code2: Service unsupported).
When the RSVP daemon accepts a new reservation, the CBQ mechanism creates a new leaf class reserving to it the bandwidth indicated in the reservation message by the token rate r parameter. In the CL class the peak rate is not specified by the receiver. These leaf classes are allowed to borrow from their parent class (cntlload class).
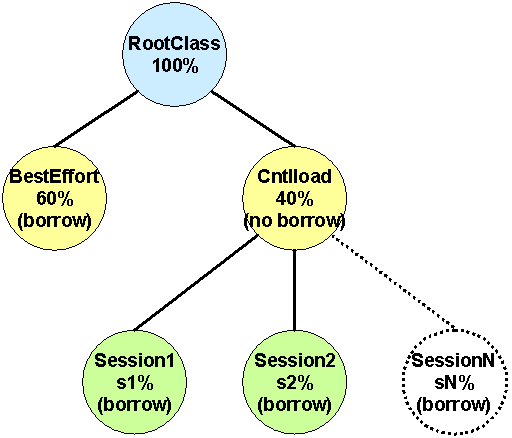
- Test configuration
For several practical problems, the reserved flow originates from Ammon to Truciolo, via Kirki. However the only reserved link is the ATM link from Ammon to Kirki (the second hop, from Kirki to Truciolo, is not reserved). First series of test involve only two reserved flows, TCP and UDP, while second series add them a third UDP flow (belonging to the Best Effort class) from Ammon to Kirki.
Graphs are performed capturing the data traffic on the Kirki ATM interface (with the tttprobe program), and showing the graphical result (with tttview) on Thud .

Reserved Traffic only: one TCP and one TCP unicast session
This plot confirms the expected results. If only one TCP flow is present it take approximately 0.5Mbps, and when an other TCP session starts the throughput of each one drops to 0.25 Mbps approximately. The TCP bandwidth is the same, both with one and two sessions.
However not the whole cntlload bandwidth is used from these two class, as already noted in the borrow tests.
Best effort and Reserved Traffic
These graphs mainly show that the reserved traffic is not affected from the best effort traffic. When no reserved session are present the best effort traffic use the whole bandwidth, but its bandwidth is reduced when reserved session starts.
Anyway, these graphs confirm that the UDP session receives less service than the TCP: first two graphs (with one UDP and one TCP session) show clearly that the UDP session use less bandwidth than TCP. Third graph, with two TCP session, shows that the bandwidth is equally shared among the two sessions.
- Conclusions
The integration of the CBQ and RSVP is very good. Unfortunately some problems arise, but these are not due to the RSVP but to the CBQ mechanism, especially to the borrow implementation. A provider that would like to adopt RSVP with CBQ must take care that the current limitation of the CBQ does not affect its performance.
- CBQ Performance
The CBQ mechanism consists of a classifier, an estimator, and a packet scheduler. Regarding to the performance issue, we can say:
- scheduler: since it is a weighted round robin, it has constant overhead
- estimator: it depends on how many flows and how much traffic is involved, and generally its overhead increases linearly according the number of classes
- classifier: its overhead depends on how many classes it manages and on how much complex is the classifier filter and, moreover, it depends on how it is engineered. Basically it increases linearly too
It has no sense to understand the CBQ latency because usually the time spent from one packet waiting in the output buffer is much bigger than the time spent in the CBQ mechanism. Even if the CBQ latency increases due to the increased number of classes, the bigger part of the time that a packet spends in a router is due to its permanency in the output buffer. So, if the goal is to limit the end to end delay, limiting the buffer length is more effective than decreasing the scheduling overhead.
However the maximum performance in terms of packet per second is an interesting test. Anyway is easy to derive, from the packet per second measurement, the latency of each packet in the router machine.
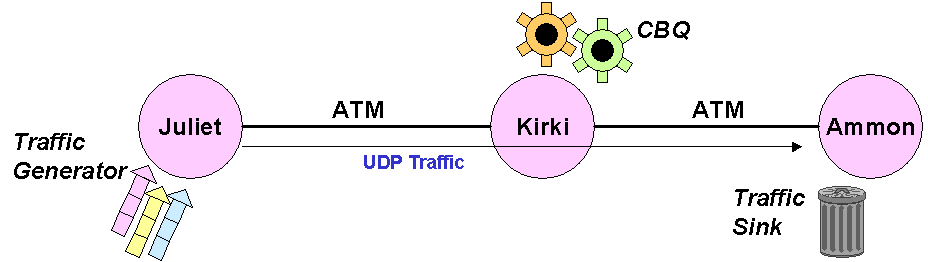
- CBQ Throughput (perf)
Is not easy no determine the CBQ throughput, for a lot of different reasons.
First of all, sending TCP traffic would be better because it doesn’t waste CPU cycles. However it’s no trivial to impose a TCP packet size: the only mean to impose a certain packet size is to set the socket buffer (TTCP –b command) to a certain value: however this is very overloading for the CPU, because with small packet size the amount of the CPU power needed is very high (each packet sent requires an acknowledge), and moreover the path latency can affect the overall throughput.
For these reason, it has been chosen the UDP flow, but with some warning. The UDP flows does not adapt itself to the network load: so, to avoid the router CPU overloading, the link between the sender and the router must be set to the appropriate speed. Generally are done two kinds of test: one where this link is set a little larger than the number of packets that the router can manage (this means that the router has to discard some UDP packet), and one where it is set a little smaller than the router capacity: in this case the number of packet in is equal to the number of packet out from the router. Anyway the use of an UDP flow means that only the flow from the source to the destination is present in the system, with no flows from the destination to the source, otherwise than TCP flows.
To measure the system performance it has been used the XPERFMON++ (with the options +systemcpu +inputpkts +outputpkts), from the BSD port collection. However the results are not quite accurate, because:
- when the router is running with high speed flows its CPU is completely overloaded and no CPU cycles are available to other programs
- the XPERFMON++ measures all the input and output packets (so also the multicast and broadcast packets arriving on the Ethernet card of each machine affect the throughput)
Therefore these performance measurements have not an high lever of precision, and must be seen as an indication of the CBQ performance. The most affordable result is in the last column: obviously the last two column should report approximately the same value (one is the number of outgoing packets from Kirki, and the other is the number of incoming packets to Ammon): this is not true for the measurement problems reported above. The more exact value is that reported in the last column, because the CPU load in Ammon is a bit lower than that in Kirki, so the result is a bit more affordable.
The CBQ configuration for this test is very simple: one class (the default class) with the 100% bandwidth. The bandwidth of the root class is the same as the Kirki – Ammon PVC. No packet size is set, because other tests showed that the packetsize parameter has no effect here.
Results
Clearly the results depend on the packet size. However it’s possible to say that the throughput with small packet size is approximately 15Kpps on an AMD K6-200 machine.
When the packet size increases, the overall performance decreases, and this is easy to understand because of the higher load to transfer the packets from the network interface to the memory and vice versa.
This result is coherent with those of the ALTQ guy: in his paper (table 1) we can deduce that with 1500MTU it has approximately 15Kpps, obtained with a more powerful machine than our.
It is important to remember that when the router machine is running at full speed no other processes receive service: this machine appears like a blocked PC.
|
UDP Payload size (byte) |
PVC Juliet – Kirki (Mpbs) |
PVC Kirki – Ammon |
Packet In (kirki) |
Packet Out (kirki) |
Packet in (Ammon) |
|
4 |
15 Mbps |
30 Mbps |
14900 |
14900 |
14900 (1) |
|
4 |
15.2 Mbps |
30 Mbps |
14750 |
14700 |
15000 |
|
4 |
16 Mbps |
30 Mbps |
15800 |
14400 |
14700 |
|
32 |
15 Mbps |
30 Mbps |
14950 |
14950 |
14950 (1) |
|
32 |
16 Mbps |
30 Mbps |
15900 |
14200 |
14700 |
|
32 |
20 Mbps |
30 Mbps |
19500 |
12200 |
12600 |
|
32 |
25 Mbps |
30 Mbps |
24100 |
10300 |
10500 |
|
64 |
22 Mbps |
40 Mbps |
14300 |
13500 |
13800 |
|
64 |
21.4 Mbps |
40 Mbps |
14200 |
14200 |
14200 (1) |
|
128 |
40 Mbps |
40 Mbps |
19900 |
10600 |
10600 |
|
128 |
32 Mbps |
40 Mbps |
16000 |
13300 |
13400 |
|
128 |
29 Mbps |
40 Mbps |
14500 |
14300 |
14400 |
(1) test where the CPU load is not 100%
- CBQ classes overload
This test use the same configuration of the above test. Goal is to understand the worsening in the CBQ mechanism when a lot of classes are involved in the system. This test use a 60Mbps PVC, with configuration with 10-20-50 and 100 classes. Each class use 0% bandwidth, except the default class that use the 100%.
Each class differ from the others for the destination port: this is a very simple filter but quite heavy to compute because it needs that every packet must be analysed quite in depth.
Results
Results show clearly a worsening when the number of classes increases. This can be a problem not in the normal use of CBQ stand alone (since the number of classes is limited because is not possible to allocate a decimal percentage of the root bandwidth), but in an RSVP environment because of its ability to create dynamically a lot of classes.
|
UDP Payload size (byte) |
Number of classes |
PVC Juliet – Kirki (Mpbs) |
PVC Kirki – Ammon |
Packet In (kirki) |
Packet Out (kirki) |
Packet in (Ammon) |
|
32 |
10 |
15 Mbps |
60 Mbps |
14950 |
14950 |
14950 (1) |
|
32 |
20 |
15 Mbps |
60 Mbps |
14950 |
14950 |
14950 (1) |
|
32 |
50 |
15 Mbps |
60 Mbps |
14400 |
13400 |
13950 |
|
32 |
50 |
14.2 Mbps |
60 Mbps |
13600 |
13500 |
14100 |
|
32 |
50 |
14 Mbps |
60 Mbps |
13900 |
13800 |
14100 |
|
32 |
50 |
13.7 Mbps |
60 Mbps |
14100 |
14100 |
14100 (1) |
|
32 |
100 |
13.5 Mbps |
100 Mbps |
13200 |
11500 |
11900 |
|
32 |
100 |
12.8 Mbps |
100 Mbps |
12700 |
11900 |
12200 |
|
32 |
100 |
12.2 Mbps |
100 Mbps |
11900 |
11900 |
12200 (1) |
(1) test where the CPU load is not 100%
- CBQ Memory load
It’s important to understand the memory requirement of the CBQ too. Unfortunately it is not clear (to me) how to measure the memory occupancy. (NOTE: I’m not sure about how to measure the memory load)
The configuration files and the machines configuration are the same of the above tests.
Results
The result, derived from the TOP and the PS program (and they are coherent among themselves) show that the memory occupancy is very low. This is not clear to me (NOTE: question mark about the memory result) because it seems to me that each class in CBQ allocates a 30 elements queue (report in CBQSTAT program). This clearly doesn’t matches with the results on the following table.
The PS UNIX command shows:
|
Number of classes |
VSZ (Virtual Size Memory) (KB) |
RSS (Real Memory) (KB) |
|
10 |
264 |
600 |
|
20 |
268 |
600 |
|
50 |
280 |
608 |
|
100 |
300 |
608 |
Equivalent results can be obtained from the TOP program, ad monitoring the Active Memory. This parameter increases of approximately the same amount of the sum of the VSZ and RSS reported by the PS. This amount of memory is fixed: in other word the presence of flows to manage doesn’t affect the memory allocation.
- Conclusions
The main problems of the CBQ package seems to be:
- the precision of the bandwidth share imposed, not very accurate
- the "typical packet size", that mean that we need to know, a priori, the medium packet size of the traffic inside each class, that in general can be much more smaller than the MTU size (audio packet but also FTP or HTTP transfers; test with Spabalda.polito.it). Often the TCP MSS is set to 536 or 1460 bytes.
- the borrow flag
- it can not permit to respect the imposed bandwidth share among all the agency
- often is not able to use all the parent bandwidth
- if flows are TCP, the share among the flows is absolutely wrong due to the fair nature of the TCP and the present realisation of the CBQ. UDP traffic vice versa is able to share the excess bandwidth with different bandwidth share
- borrow works bad when the flows have different packet size (the smaller packet size can use more bandwidth than the other)
- some problem seems to exist with UDP flows, that performs bad compared to the TCP
- the CBQ mechanism tends to transmit packets with burst (if one class is backlogged, CBQ transmits packet for that class until it reaches the maximum allowed). This behaviour has three main effects:
- it increases the medium latency of the CBQ sessions (that is a problem with multimedia applications)
- it increases the possibility of packet losses in the next routers in the path (if the traffic become more burstly; NOTE someone ??? studied this…)
- it increases the TCP windows size management problems, because the flow has not constant throughput so the retransmission time has to continuously adapt itself to the network behaviour
Note: Test with
- different priority????
- "Efficient" flag???
- Packet Round Robin ???
NOTE
When the NOTE word is found somewhere in this report, it means that something can be wrong, if can be something to do, or I’m not sure of that I’ve written …